



Introduce commands when Debezium is operated
Debezium can retrieve changes of DB like insert, update, delete, etc and send messages to a messaging service like Kafka.
When we use and operate Debezium, some questions is came up to correctly operate this service.
For example, we’ll be worry abou know how to stop and start Debezium safely.
In this artcicle, I’ll explain such kind of commands and manuals when we operate Debezium.
For experiments purposes, Debezium and Kafka are mainly used.
If you wanna know details of Debezium, please confirm the following document.
https://debezium.io/
Purpose
- Introduce the overview how to communicate between Debezium and Kafka
- Introduce how to stop/start Debezium safely
Target of subscriber
- Person who is considering to use Debezium & Kafka
- Person who is worring about how to safely restart Debezium
The mechanism overview of Debezium & Kafka
This is just rought overview of each service mechanism.
But it’ll help understanding of operation.
Perhaps, a detail mechanism is depend on a design pattern of your implementation.
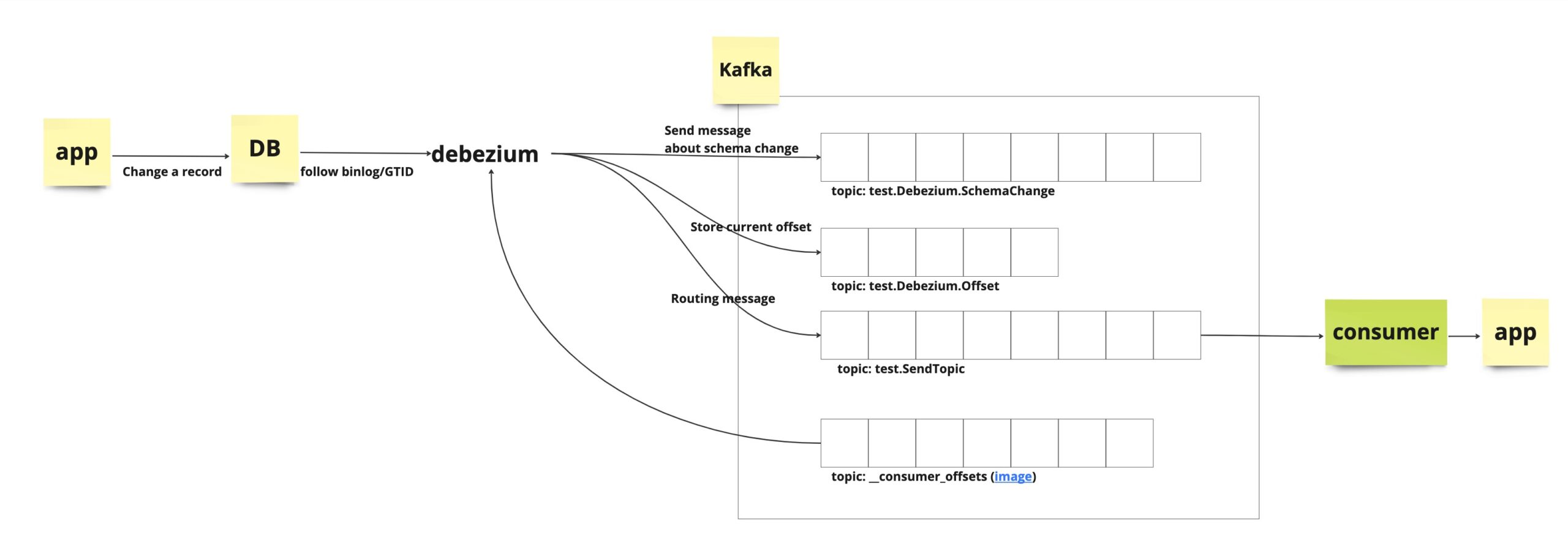
- Application changes a record in DB
- Binlog/GTID in DB is proceeded
- Debezium detect the change of DB based on binlog/GTID
- Debezium send a message to Kafka
- Consumer who subscribes a topic receive the message from Kafka
- Application who recieve a event from the consumer take an action
Additionally, other metadata about Debezium like changing info of schema, an offset info that Debezium has read a message also is stored to the Kafka topic.
Confirm behavior via hands on
You can begin Debezium along with the following document.
https://debezium.io/documentation/reference/stable/tutorial.html
And, the following document is helpful for you when you begin hands on at the first time.
https://zenn.dev/stafes_blog/articles/ikkitang-691e9913644952
The above document describe how to do the hands on clearly, so I also use this one.
Concering points during operation of Debezium
This section will explain the concern based on the hands on using the following document when we operate Debezium.
Basically, I’ll use Kafka Command-Line Interface Tools to collect information about Debezium.
https://docs.confluent.io/kafka/operations-tools/kafka-tools.html
How can we confirm a status of Debezium?
Confirm a status of Connector (ref)。
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status
{"name":"debezium-sample-connector","connector":{"state":"RUNNING","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.19.0.5:8083"}],"type":"source"}%How can we stop/start Debezium?
Suspend and resume a connector
Suspend
~/D/g/debezium ❯❯❯ curl -X PUT http://localhost:8083/connectors/debezium-sample-connector/pause main ◼
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status main ◼
{"name":"debezium-sample-connector","connector":{"state":"PAUSED","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"PAUSED","worker_id":"172.19.0.5:8083"}],"type":"source"}% Resume
~/D/g/debezium ❯❯❯ curl -X PUT http://localhost:8083/connectors/debezium-sample-connector/resume main ◼
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status main ◼
{"name":"debezium-sample-connector","connector":{"state":"RUNNING","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.19.0.5:8083"}],"type":"source"}%Stop Debezium pod
In case of Debezium on k8s, it’s ok to just stop the pod.
What should we confirm after restart Debezium?
There are some perspective to confirm status of Debezium.
- Whether status of Debezium is
Running - Whether current offset of Debezium is correct (confirm there’s no duplicated data’)
- Whether Sucscriber can receive the latest message
Whether status of Debezium is Running
You can see the commands from "How can we confirm a status of Debezium?" section.
Whether current offset of Debezium is correct
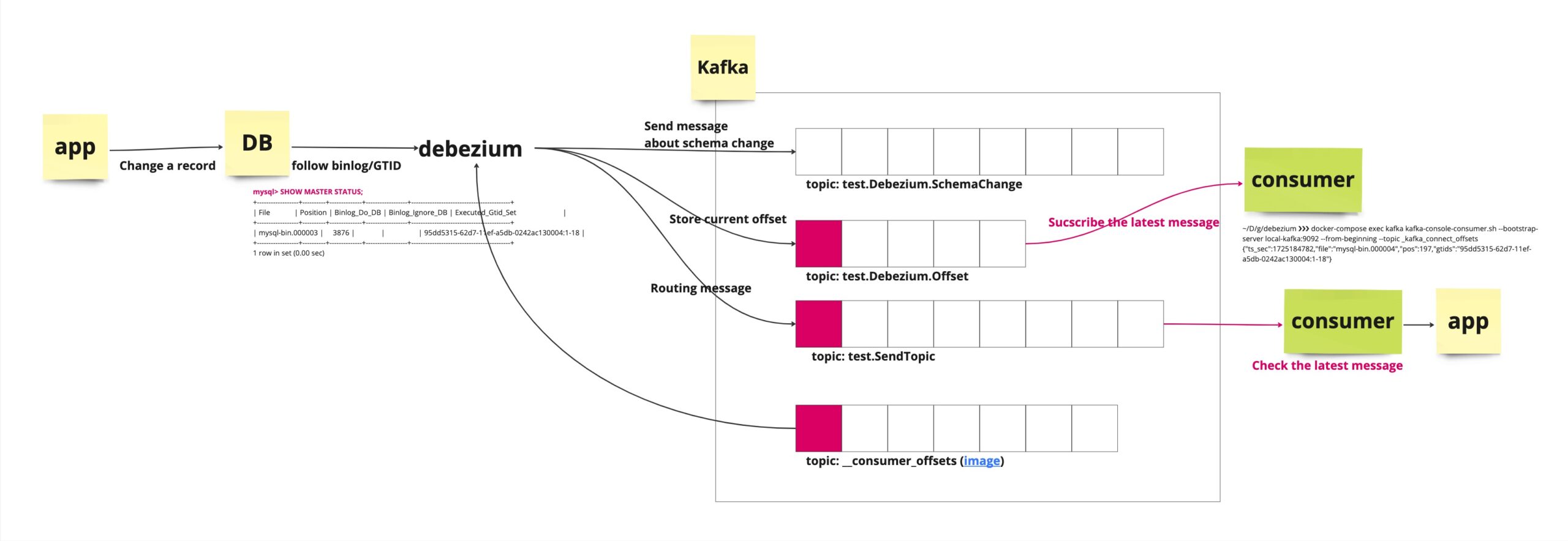
We have to confirm that two GTID between DB and Kafka which has the topic to manage the offset of Debezium.
In case of MySQL
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------------------------------+
| mysql-bin.000003 | 3876 | | | 95dd5315-62d7-11ef-a5db-0242ac130004:1-18 |
+------------------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec)This is just additional info. In case of MySQL, I recommend you to enable GTID because even if a current binlog file will be changed, Debezium can read changes from correct position if you’re using GTID.
ref: https://debezium.io/documentation/reference/stable/connectors/mysql.html#enable-mysql-gtids
Debezium
You can set the topic name which manage a offset of Debezium from environment variable as OFFSET_STORAGE_TOPIC when you start Debezium.
ref: https://hub.docker.com/r/debezium/connect
Start a consumer which subscribe the toppic.
~/D/g/debezium ❯❯❯ docker-compose exec kafka kafka-console-consumer.sh --bootstrap-server local-kafka:9092 --from-beginning --topic _kafka_connect_offsets
{"ts_sec":1725184782,"file":"mysql-bin.000004","pos":197,"gtids":"95dd5315-62d7-11ef-a5db-0242ac130004:1-18"}After that, let’s confirm that GTID will be matched.
Note
In case of using Aurora on AWS, Aurora RDS will receive requests for heartbeat.
By this, there is possibility to happen a change that GTID will be proceeded even if application has never changed the DB.
If your GTID isn’t matched, let’s also suspect the above situation.
Whether Sucscriber can receive the latest message
To check this perspective, you must operate the application side and confirm logs which include something information that what’s information has received from Kafka.
(A design of log is important…)
Duplication of message won’t be happen when Debezium restarted?
Basically, it won’t be happened because Debezium and Kafka has metadata to manage current offset.
Management of offset from Kafka
Kafka has a topic like __consumer_offsets and each Subscriber can know current offset of each topic.
ref: https://kafka.apache.org/documentation/#impl_offsettracking
key is [Group, Topic, Partition].
If these key will be match, a subscriber can consume messages correctly after restart.
The following page is helpful for you to konw more detail.
ref: https://stackoverflow.com/questions/56947184/how-does-consumer-offsets-keep-offset-for-two-consumers
Exception
I explained like the above, but in case Debezium or Kafka was crashed suddenly, there is possibility to happen an duplication of sending messages.
ref: https://debezium.io/documentation/faq/#what_happens_when_debezium_stops_or_crashes
So that, an application shoud consider that this possibility and need to implement the feature which can avoid duplication of message from application side.
ref: https://debezium.io/documentation/faq/#why_must_consuming_applications_expect_duplicate_events
Conclution
This time, I have summarized some points that are likely to be of concern when actually operating Debezium.
I also did a brief initial investigation on Kafka. There are several terms used in Kafka, such as "Consumer" and "Subscriber," which have caused some confusion. If there are any errors in my usage of these terms, I would appreciate it if you could discreetly point them out.
Thank you for reading up to this point.



