




はじめに
負荷試験のツールとして、k6は便利です。
そんなk6ですが、単体で利用すると、同一シナリオの異なるVU(Virtual User)間でのみmutableな値を共有する方法がありません。
本記事では、Redisを用いて上記の課題を解決する方法を紹介します。
背景: VU毎に1行だけCSVを先頭から順番に読み込ませたい
モチベーション
ログイン処理や特定のデータ入力処理等のシナリオを想定した場合、各シナリオ毎にログイン情報等を管理したCSVファイルを準備して、VU毎に1行だけCSVファイルを先頭から順番に読み込ませたい。ということがあります。
更に、VUは、1度目のイテレーションの場合にのみ、CSVファイルからデータを読み込ませたいです。
同一VUの1周目と2周目のイテレーションで、ログインするユーザが変わってしまうのもおかしな話なので、これを避けたいわけです。
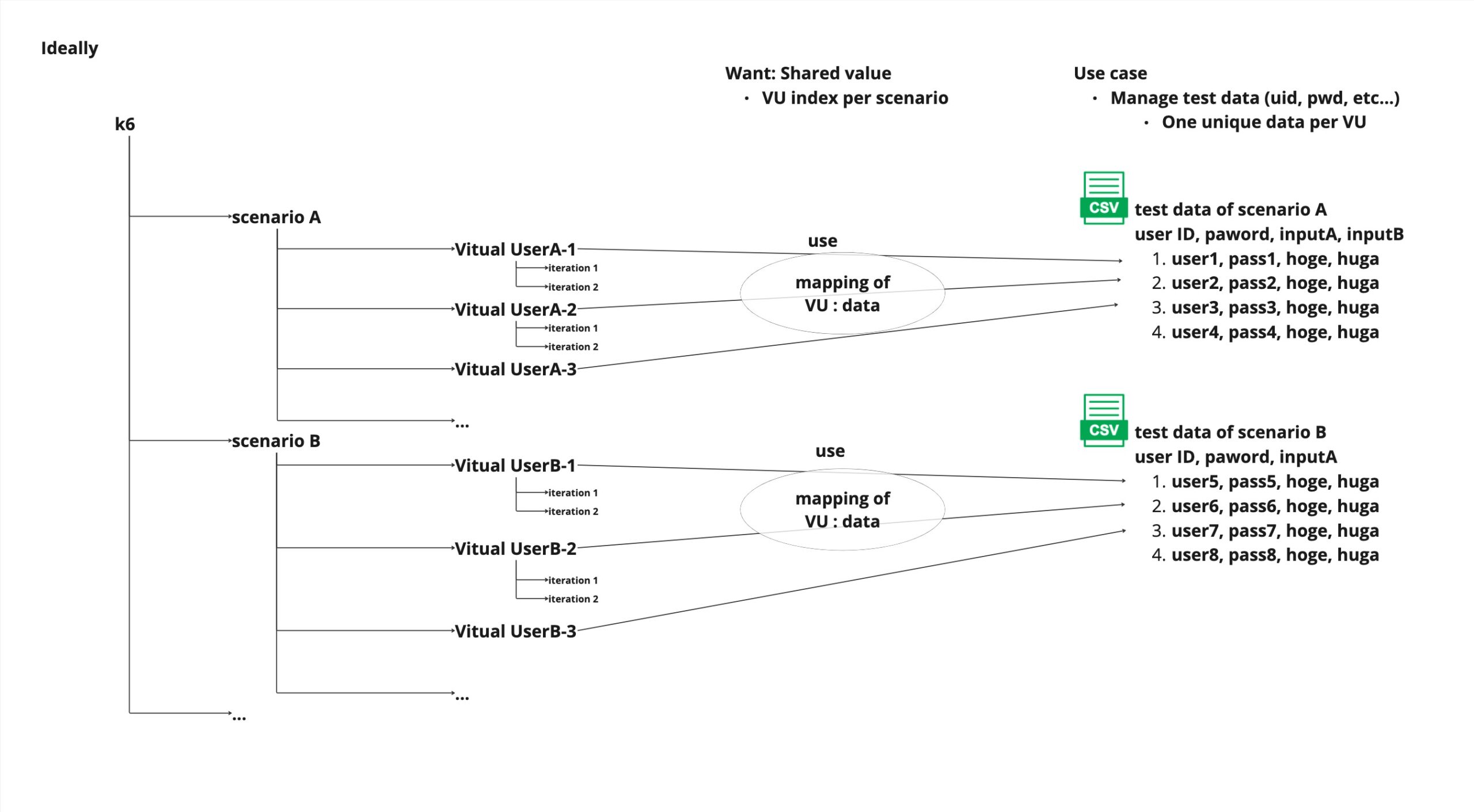
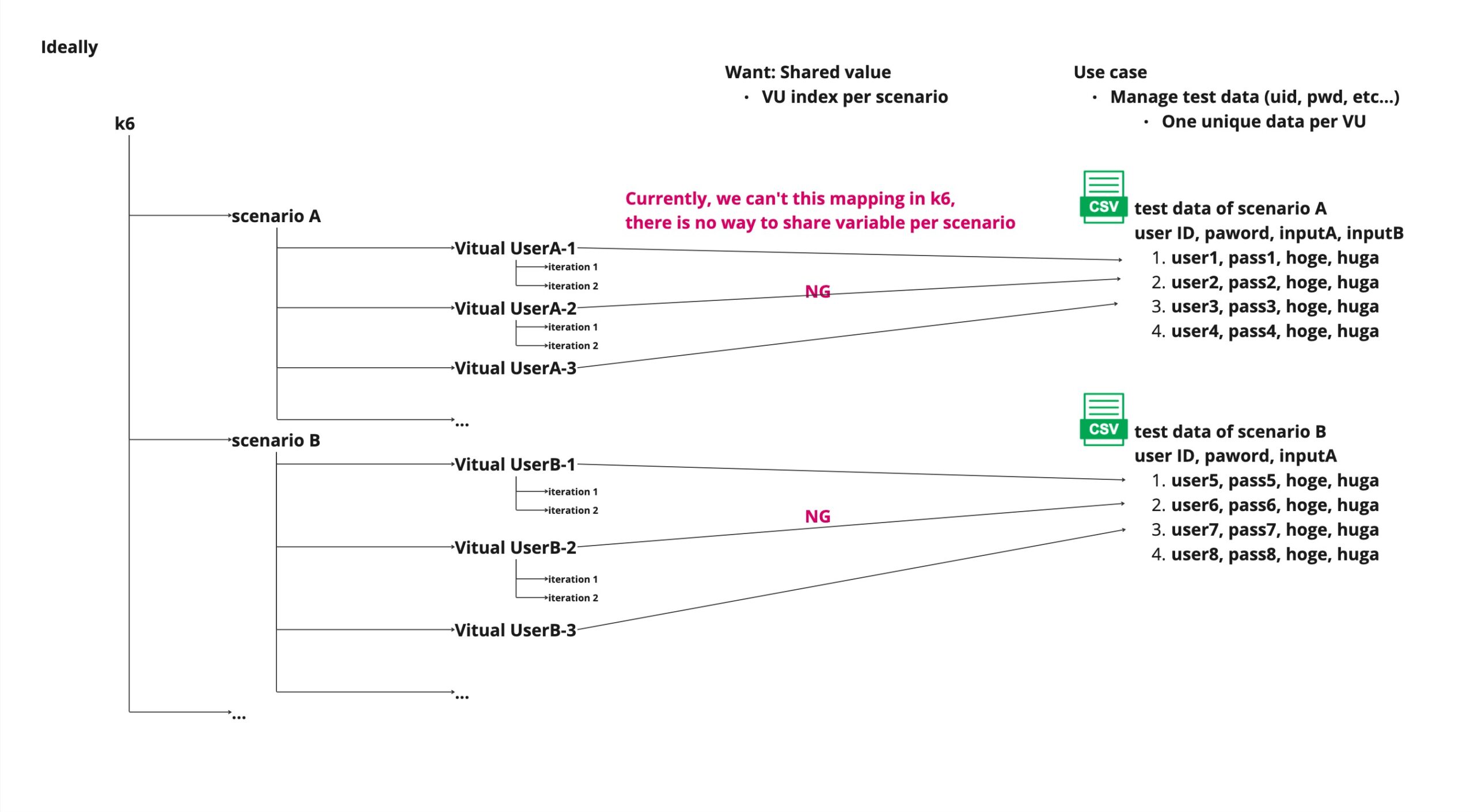
上記を実現するには、以下の要件を満たしたvariableを持つ必要があります
- 同一シナリオ内で、VUがCSVファイルを何行目まで読み込んだのかのindex情報
- 上記の情報は、シナリオ毎に独立して保持される
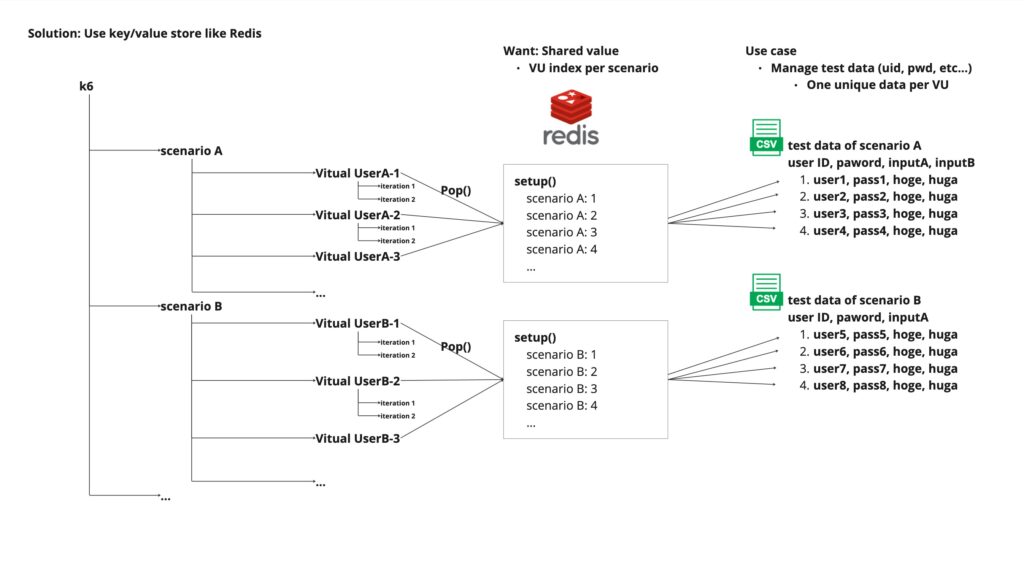
イメージ図を描くとすると、以下の通りです。
k6にはCSVファイルを読み込んでVUに渡す方法として、sharedArrayがあります。
https://grafana.com/docs/k6/latest/javascript-api/k6-data/sharedarray/
このsharedArrayに対して user[ 0 ], user[ 1 ], … という風にindexを指定して、その時々のユーザ情報を取得する形となります。
しかしながら、このsharedArray自体はimmutableな要素であり、ユーザデータを1個消費するためにpop()して… なんてことは出来ません。
そのため、我々はsharedArrayのindexを適切に設定するための何らかの情報が必要です。
現状の課題
現状(2024/03/17 執筆時点)では、以下の要件を満たす情報を、k6だけでは用意出来ません。
- 同一シナリオ内で、VUがCSVファイルを何行目まで読み込んだのかのindex情報
- 上記の情報は、シナリオ毎に独立して保持される
gatlingのような他の負荷ツールでは出来ることが、k6では出来ないのです。
(k6はクラウドでの利用や、負荷ツール自体を分散的に扱うことを想定しているようで、このような情報をk6内に持たせることを良しとしていないようです。)
当然、同じような使い方をしたい人は多いようで、コミュニティでもディスカッションされています。
以下は、私と全く同じ悩みを抱えています。
やり取りを見る限りだと、この問題が解決していないようです。
https://community.grafana.com/t/shared-state-or-unique-sequential-vu-index-per-scenario/97349
国内の記事を漁ってみたものの、CSVファイルのインデックス部分はランダムな値を生成して設定しているケースばかりでした。この場合だと、VUの並列数が増えると、ユーザの衝突も発生しやすくなってしまいます。
(もしかしたら、私のやりたいことがズレていて、ユーザは基本的にランダムで与えるのが適切なのかもしれません…)
以下のディスカッションでは、各ユースケースをサポートしているかどうかについて、それぞれまとめられています。
(2022年のディスカッションです)
https://github.com/grafana/k6/issues/1539#issuecomment-1022105636
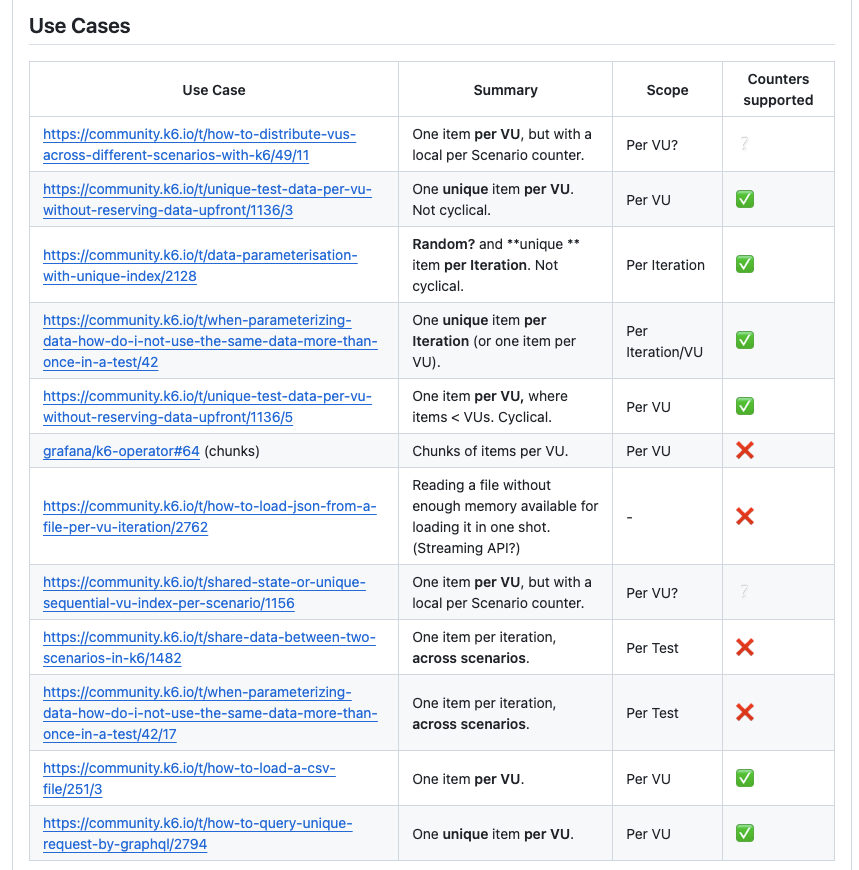
以下の内容が本記事でやりたいことに最も近しいです。
One item per VU, where items < VUs. Cyclical.
https://community.grafana.com/t/when-parameterizing-data-how-do-i-not-use-the-same-data-more-than-once-in-a-test/99720
とはいえ、CSVデータを順番に読み込ませる事はできず、VU間でユーザデータが衝突してしまう可能性は避けられません。このように、いくつかのハック的方法はあるものの、それぞれの案は課題を根本的に解決するものではなく、デメリットを抱えています。
いくつかの例を、デメリットと共に紹介しましょう。
k6 APIのexecution.scenario.iterationInTestメトリクスを利用する
k6 APIでは、実行時のシナリオやVUに関するいくつかのメトリクスを提供しています。
URL: https://k6.io/docs/javascript-api/k6-execution/#scenario
以下は、「Counter: scenario.iterationInTest」を利用した例です。
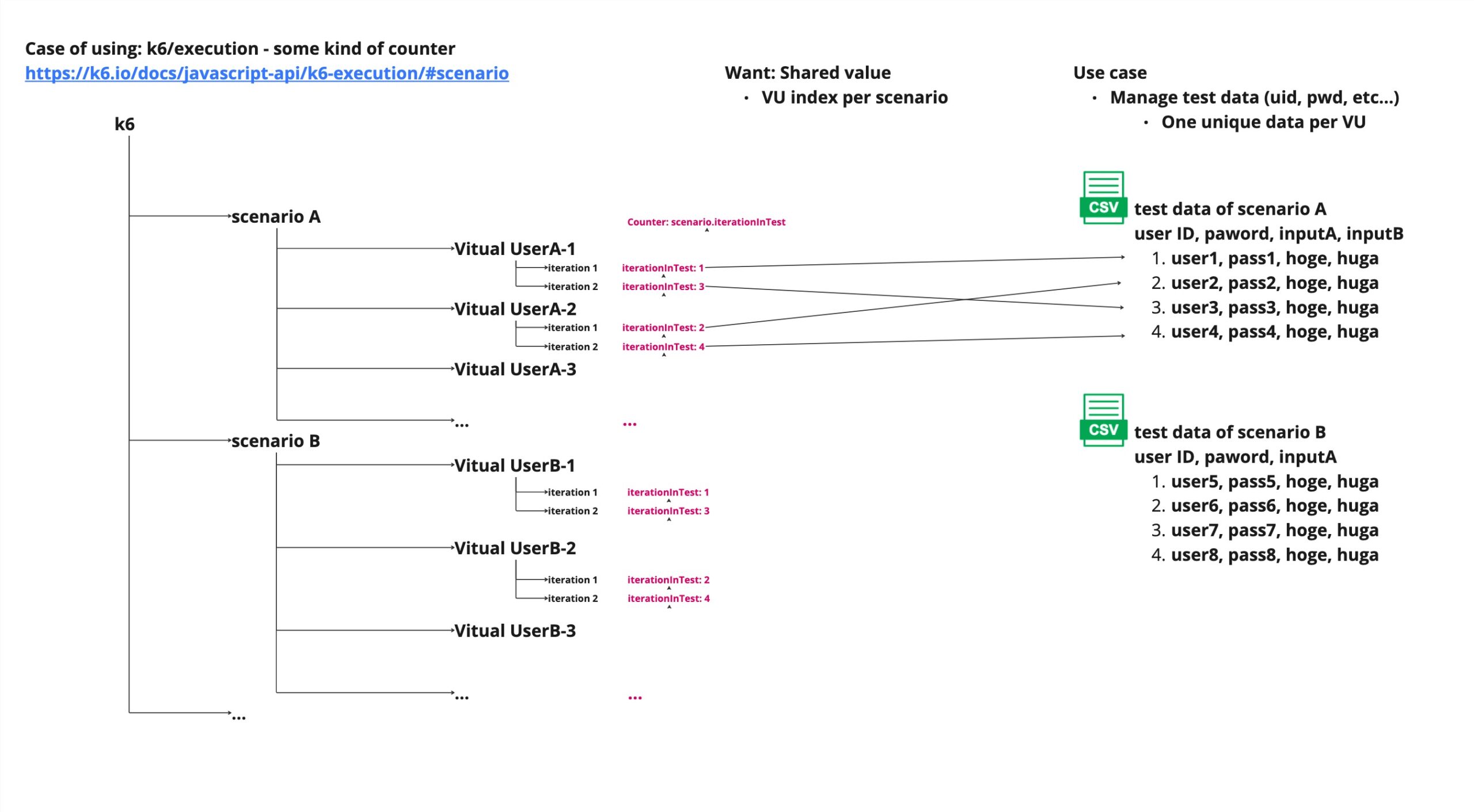
このCounterは該当のシナリオが実行された回数を、シナリオ毎にインクリメントします。
このメトリクスを扱いつつ、VU毎にイテレーションの1度目(vu.iterationInScenarioを使って取得可能)にのみCSVからデータを読むことで、ユーザの衝突は発生しなくなります。
ただし、この場合は、VU * イテレーションの回数 の数だけデータを準備する必要があります。
実際に扱われないデータも大量に発生するので、データの仕込みが大変な性能試験の場合には向かない手法でしょう。
k6 APIのexecution.vu.iterationInTestメトリクスを利用する
https://k6.io/docs/javascript-api/k6-execution/#vu
以下は、「Counter: vu.iterationInTest」を利用した例です。
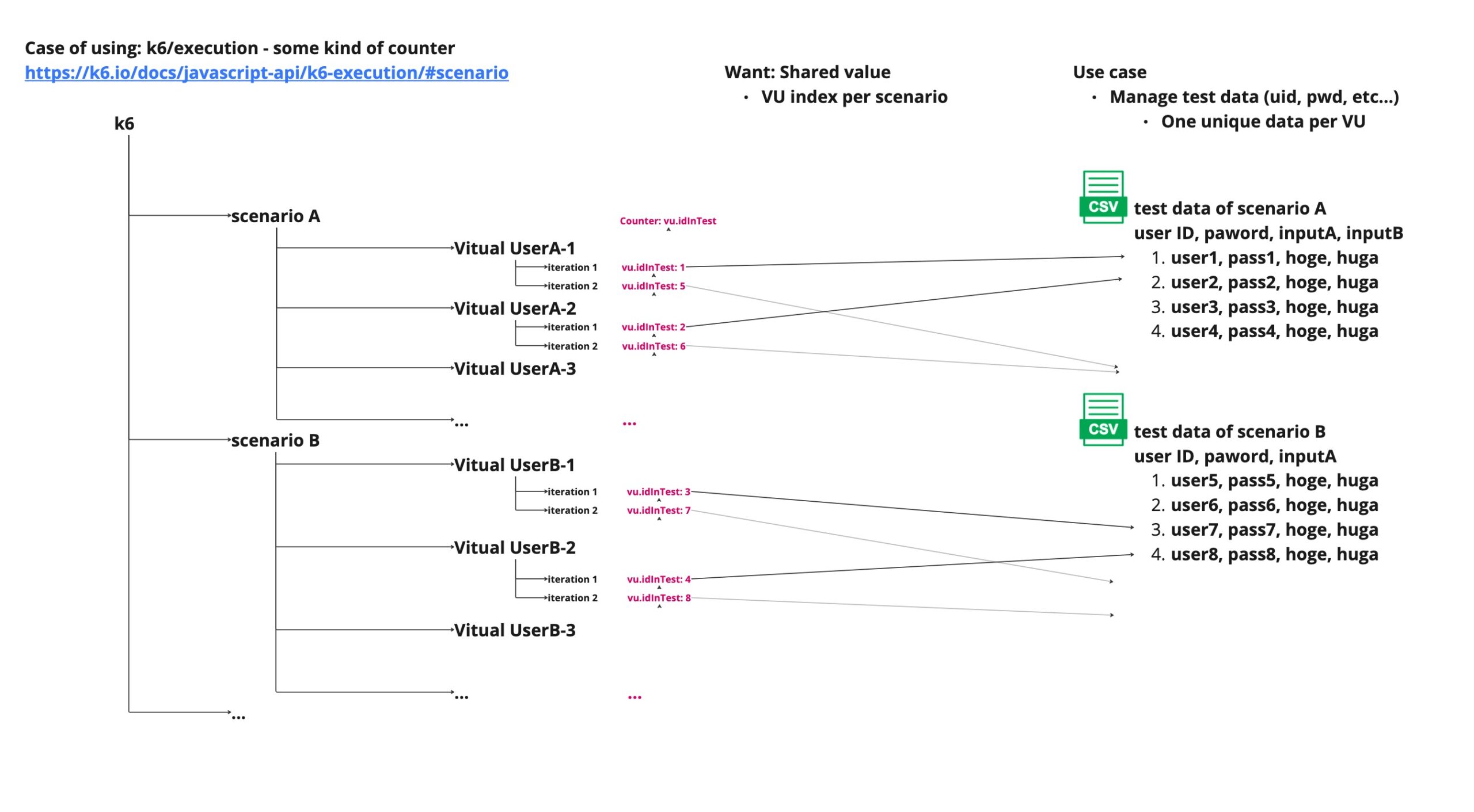
このCounterは全てのシナリオで扱われるVUに対して、一意に付与される値です。
つまり、この値はVU間で重複することはありません。
ただし、この場合は、全てのシナリオで扱われるVUの数だけ、データを準備する必要があります。
1つ前の方法と同様に、データの仕込みが大変な性能試験の場合には向かない手法でしょう。
k6 APIのexecution.vu.iterationInScenarioメトリクスを利用する
https://k6.io/docs/javascript-api/k6-execution/#scenario
以下は、「Counter: vu.iterationInScenario」を利用した例です。
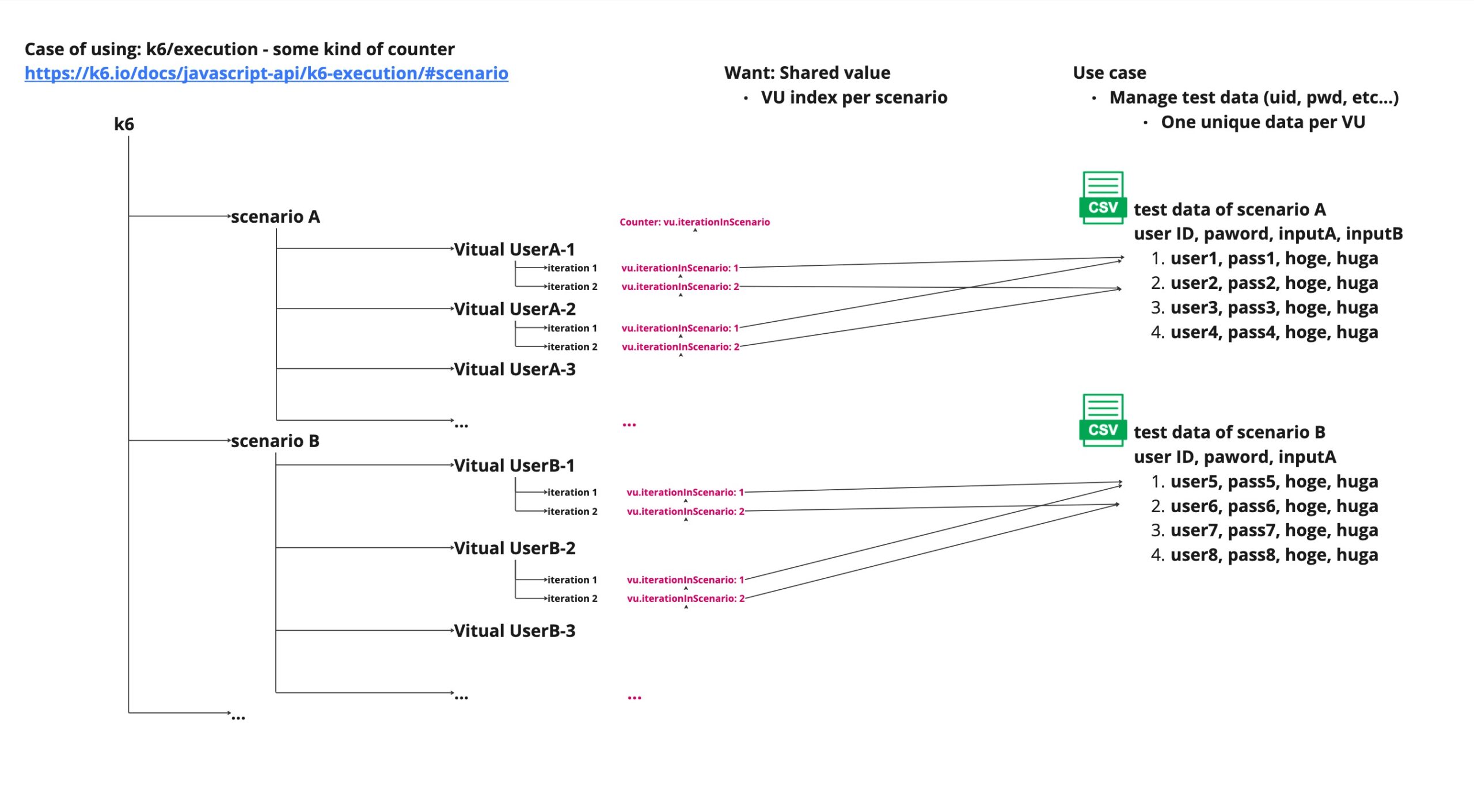
CounterはVUが実行中のシナリオを何度イテレーションしたのかをカウントしています。
この場合、図を見ると分かるように、VU1とVU2のデータが衝突してしまいます。
VUが各シナリオに1人しか存在しない場合には、この方法でも問題ありません。
(負荷試験を行うにあたって、そのような条件は存在しないと思われますが…)
その他のボツ案
上記で挙げた例の他にも、コミュニティを漁っていると、利用出来そうないくつかの機能が見つかります。
- xk6-counter
- https://github.com/mstoykov/xk6-counter
- シナリオ全てで共有されるカウンターです
- ユーザデータを大量(= VUの総量分)に準備出来る場合には、この方法でも問題無いでしょう
- k6-cloudでは扱えません。ローカルの1インスタンスで動かす場合に限定されます。
- xk6-kv
- https://github.com/oleiade/xk6-kv
- ローカルインスタンス内にKey/Value storeを持つことが出来ます
- シナリオ毎に、インデックスをset/get/deleteするという使い方が出来ます
- pop()で値を取得することは出来ません
- CSVのインデックスをこれで管理することは不可能です
- 排他制御が出来るわけでもなく、VUの多重度が増えた際に、正確なインデックスを取得するのは不可能
k6には便利なメトリクスや拡張機能があるものの、今回の課題を解決することは出来ません。
こうなってくると、k6単体ではどうにも出来ず、外部のデータストアでステート管理するべきであることが分かってきます。
ちなみに、以下のコミュニティでのディスカッションを参考に、Express, MySQLでシナリオ毎のインデックスを管理する外部サービスも立ててみました。
https://community.grafana.com/t/unique-test-data-per-vu-without-reserving-data-upfront/97144/4
しかしながら、DB側で排他制御も考えつつ、VUの多重度にも耐えるとなると、負荷試験のボトルネックになってしまうことも懸念されるので、今回は選択しませんでした。
解決策: Redisを使おう
前置きが大分長くなってしまいました。
いよいよ本題です。
k6単体では解決しない、APIサーバを立てるとなるとボトルネックになる危険性もある…
そこで、速さと完全性を兼ね備えたデータストアとしてRedisを利用するのが適切と考えました。
幸い、k6ではRedis操作用のClientも提供してくれているので、簡単に扱えそうです。
https://grafana.com/docs/k6/latest/javascript-api/k6-experimental/redis/
イメージは冒頭でも示した通りですが、再掲です。
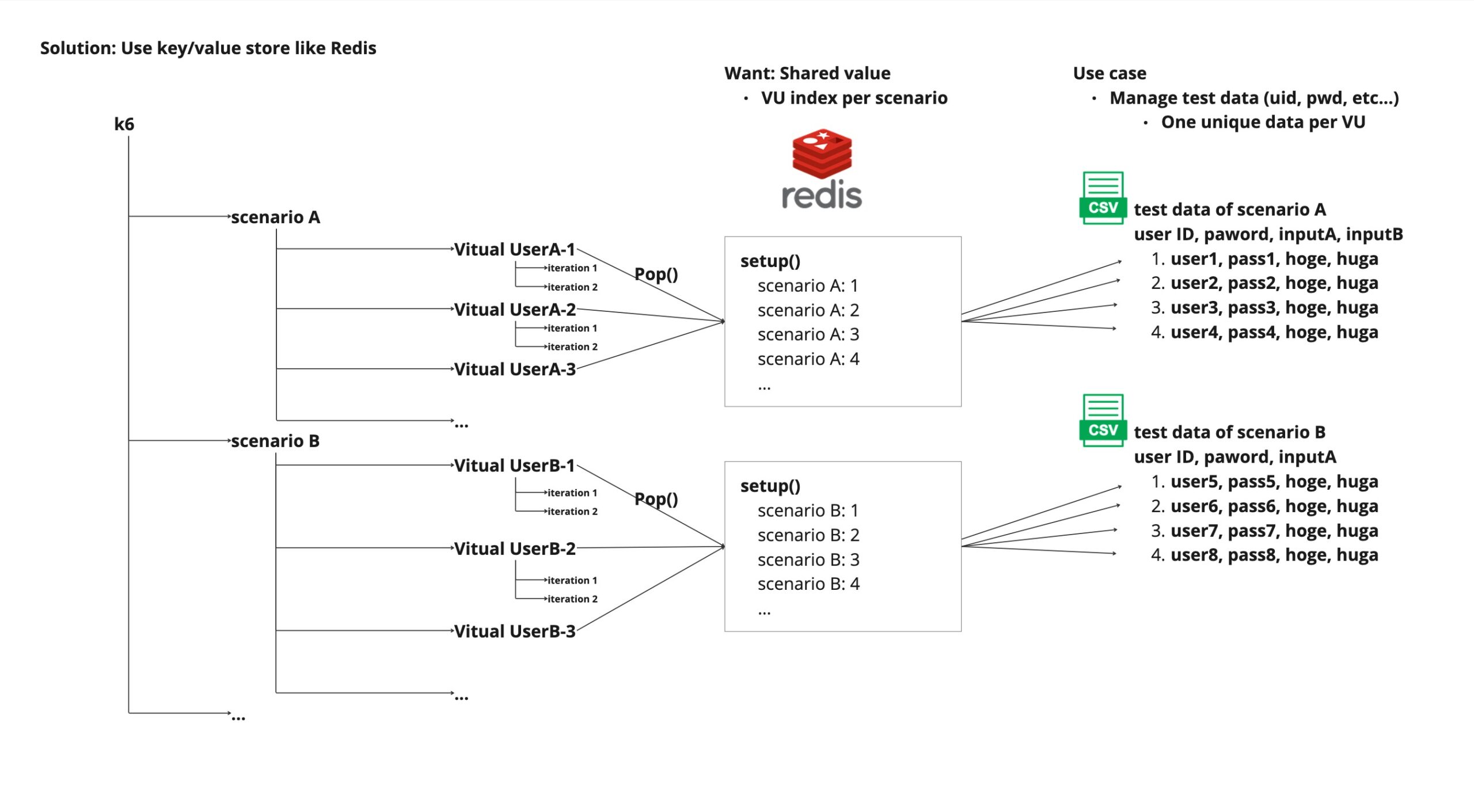
シナリオが開始する手前のsetup()の中で、事前に全てのシナリオで利用するインデックス番号を (シナリオ名, インデックス番号)の形でRedisに入れておきます。
後は、シナリオの中で該当のシナリオのインデックスをpop()することで、先頭から順番にインデックスを取得して、期待通りにCSVファイルからデータを読み込む事ができます。
(ローカルで1000並列で試した感じは、重複も起きずに問題ありませんでした)
Redis自体はローカルだったらサクッと建てられます。
公式: https://redis.io/docs/install/install-redis/
以下、k6のコードのサンプルイメージです。
シナリオ開始前に1度だけ呼び出されるSetup()の中で、Redisへデータを詰め込んでおきます。
import redis from 'k6/experimental/redis'
const client = new redis.Client('redis://localhost:6379')
export async function Setup(): Promise<void> {
for (let i = 0; i < amountOfScenarioIteration; i++) {
await client.rpush('scenarioA', i)
}
}
シナリオの中では、一度目のイテレーションの場合にのみ、データをPopしてきて、CSVのインデックスとして利用します。
import { SharedArray } from 'k6/data'
import papaparse from 'https://jslib.k6.io/papaparse/5.1.1/index.js'
import redis from 'k6/experimental/redis'
const client = new redis.Client('redis://localhost:6379')
// Manage whether current iteration is first or not
let roopCounterPerVU = 0
const users = new SharedArray('atTimesIndex', function () {
return papaparse.parse(open(`${SCENARIO_FILES_DIR()}/userdata.csv`), { header: true }).data
})
export default async function ScenarioA(): Promise<void> {
if (roopCounterPerVU === 0) {
const counter = await client.lpop('scenarioA')
user = users[counter]
}
roopCounterPerVU++
}
このようにシナリオを構成するだけで、VU毎に1行だけCSVファイルを先頭から順番に読み込ませる。ということを実現出来ます。
まとめ
いろんなページを漁ったり、公式ドキュメントを漁ったりしながら、数日かけて悩んでいました。
Gatlingだったら簡単に出来るのに… k6はなぜ….?
これはJavaScript上の仕様もあるのかな…? あぁJavaScriptが嫌いになりそう….
などなど、いろんな想いを張り巡らせていました。
同じ悩みを持った方が、数時間で悩みを解決出来ますように…
ここまで見ていただき、ありがとうございました。





