




Lambdaからseleniumを動かすための環境構築の手順、設定方法を紹介します。
ハマるポイントとしては、以下の箇所で躓く方が多いのではないでしょうか?
- Lmbda上の関数から外部のモジュールをインポートする方法
- Lambdaで動作するseleniumとpythonの相性問題
そんな難しくないでしょう?と思って設定していたら、土日を潰してしまったので、同じ悲しみを味わう方が減るように、この記事に残します。
それでは一から設定していく手順を紹介します。
前提
今回、動作確認に使用するLambda関数は以下の通りです。
#coding: UTF-8
import os
import time
import pytz
from selenium import webdriver
from selenium.webdriver.chrome.options import Options # オプションを使うために必要
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.common.by import By
from datetime import datetime, timedelta
import warnings
warnings.filterwarnings('ignore')
CHROMEDRIVER_PATH = os.environ["CHROMEDRIVER_PATH"]
HEADLESS_CHROMIUM_PATH = os.environ["HEADLESS_CHROMIUM_PATH"]
def lambda_handler(event, context):
options = webdriver.ChromeOptions()
options.add_argument("--disable-gpu")
options.add_argument("--hide-scrollbars")
options.add_argument("--ignore-certificate-errors")
options.add_argument("--window-size=880x996")
options.add_argument("--no-sandbox")
options.add_argument("--homedir=/tmp")
options.add_experimental_option("w3c", True)
options.add_argument("--headless")
options.add_argument("--single-process") # if enable this option, it doesn't work in local
options.binary_location = HEADLESS_CHROMIUM_PATH
driver = webdriver.Chrome(
executable_path=CHROMEDRIVER_PATH,
options=options
)
driver.get("https://www.google.com/")
driver.quit()
いくつか、本メソッドの中で使用していない関数もありますが、多分seleniumでスクレイピングする上で後々必要になることが多いと思うので、このまま残しておきます。
手順
エラードリブンに作った方が、筆者の躓いたポイントを追体験できると思いますので、そのように進めていきます。
まずはLmabda関数を作る
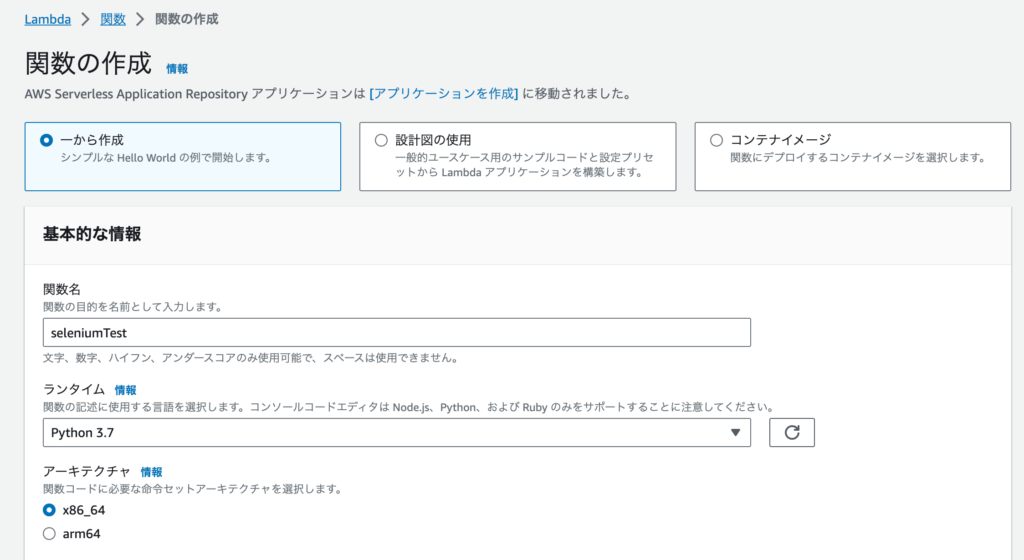
「関数の作成」から新しくLmabda関数を作成しましょう。

関数名は何でも良いです。
「seleniumTest」とでもしておきましょう。
ランタイムは重要です。どうやらseleniumを動かすための相性がいいpythonのバージョンが3.7.3なので、ランタイムはpython 3.7を指定します。
関数が作成されたら、前提に記載したコードをlambda_function.pyに貼り付けます。
「Deploy」を押してソースコードを反映させた後、「Test」を選択します。
とりあえずエラーが表示されることを確認するために、「testEvent」という名前でテストイベントを作成しましょう。
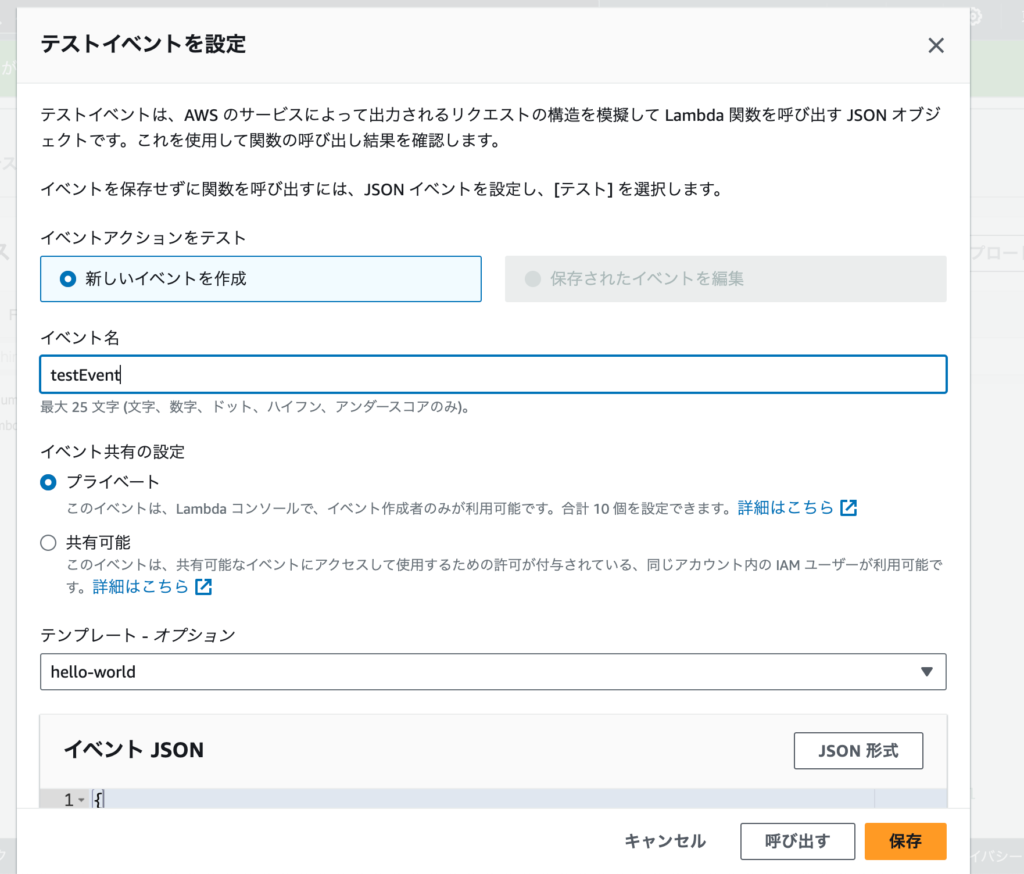
再度、「Test」を実行します。
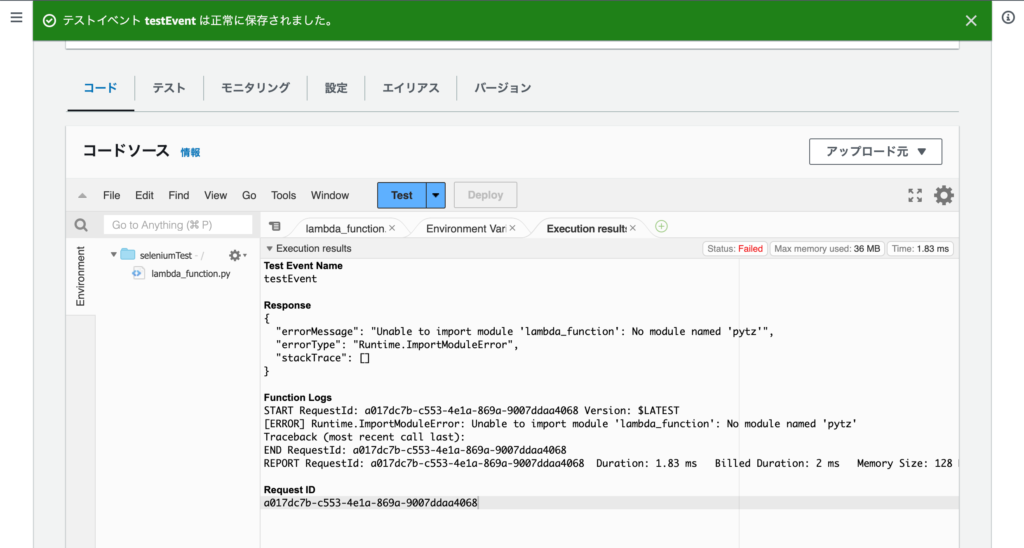
以下のエラーが表示されるはずです。
モジュールをインポートできていないので、当然といえば当然のエラーです。
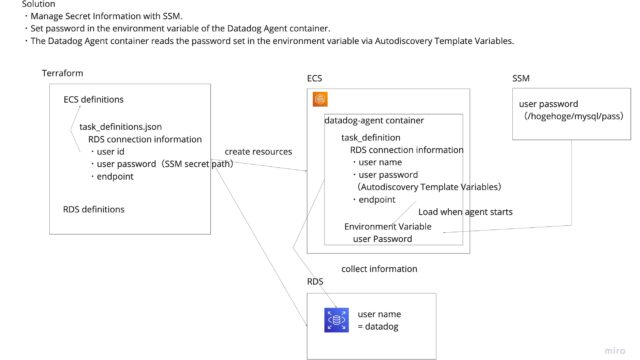
ここで、ハマるポイント1の「Lmbda上の関数から外部のモジュールをインポートする方法」を学ぶ必要があります。
いくつか方法があると思いますが、Lambdaにレイヤーを設定し、外部モジュールをインポートします。こうしておくことで、他のLambdaを作成した際に同様のレイヤーを使い回せるので、環境構築がグッと楽になります。
レイヤーを使って関連モジュールをインポートする
ローカル環境で関連モジュールをインストールしたzipファイルを作成し、それをLambda上にアップロードします。
ローカル環境に依存したエラーを出したくはないので、Docker上でpython用のコンテナを起動し、その中で必要なファイルを作成します。
(ローカル環境でDockerを起動できない状態の場合、別途準備をお願いいたします)
まずはPythonのDockerイメージをローカル環境に持ってきて、起動しましょう。
# Dockerイメージをローカルに持ってくるdocker pull python:3.7# Dockerコンテナを起動するdocker run -itd –name python3.7 python:3.7# Dockerコンテナに入るdocker exec -it python3.7 /bin/bash
Dockerコンテナの中で以下のコマンドを実行し、必要なパッケージをインストールしてからZipに固めます。
# 作業用ディレクトリを作成
cd var/tmp
mkdir python# 必要なパッケージをインストールする
# seleiniumのバージョン指定も大事です
# 4.1.0で動くことは確認できているのでそのバージョンを指定してインストールする
# 他にも必要なパッケージがあれば、ここに追記していきましょう
python3.7 -m pip install selenium==4.1.0 urllib3==1.26.15 pytz -t python/# zipコマンドが入っていないので入れる
apt update && apt install -y zip# lambda側にインストールできるようにzipで固める
zip -r layer.zip python
Dockerコンテナ上でlayer.zipを作成できたら、ローカル環境にコピーしてきましょう。
(以下のコマンドはローカル上で実行します)
docker cp python3.7:/var/tmp/layer.zip ./
これで手元のローカル環境にlayer.zipファイルがある状態になるはずです。
次に、Lambda上でレイヤーを作成します。
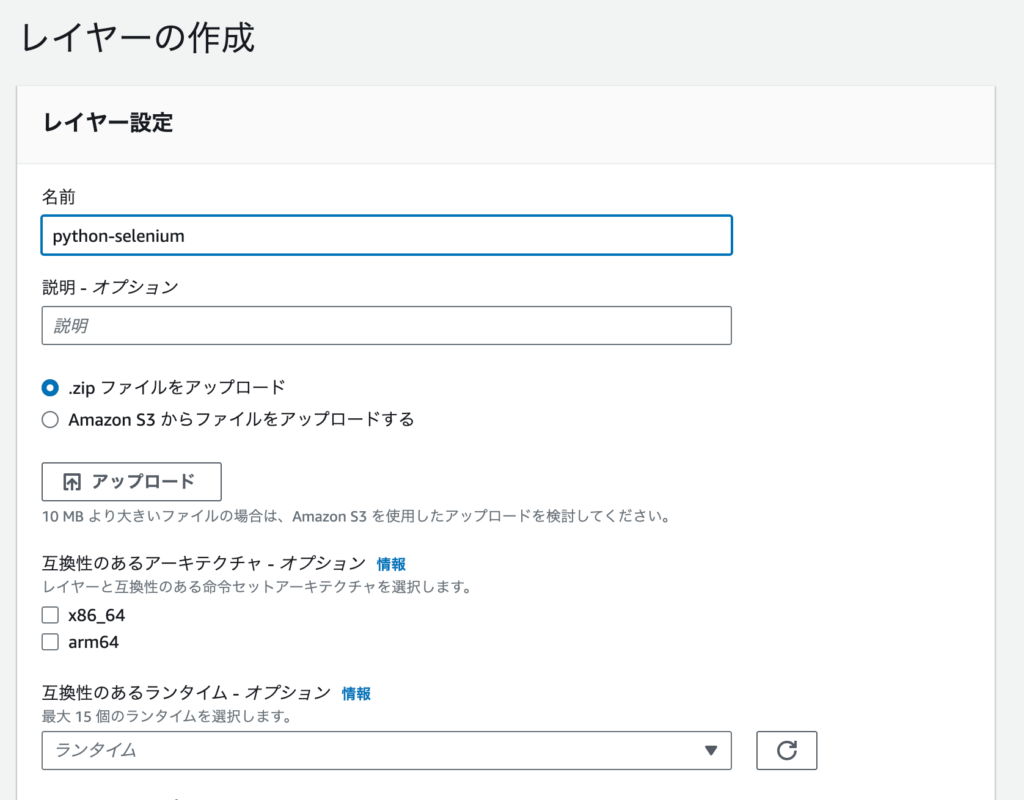
「レイヤーの作成」を選択します。

適当にレイヤー名を設定します。
とりあえず「python-selenium」とでもしておきましょう。
先程のZipファイルをアップロードします。
互換性のあるランタイムオプションには「python 3.7」を指定しておきます。
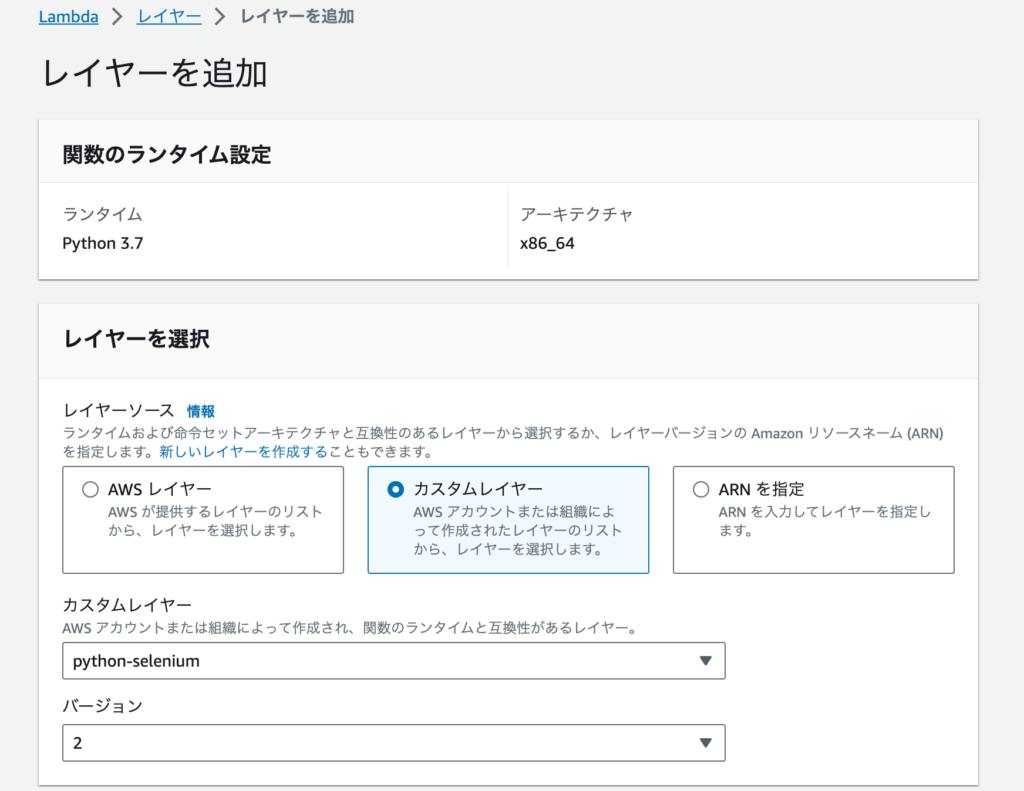
lambdaの関数画面の下部に「レイヤー」という欄があるので、ここから「レイヤーの追加」を選択します。

先程設定したレイヤーを設定しましょう。
この時点でLambdaの実行するとどうなるでしょう。
「Test」を押してみましょう。
またまたエラーになりましたね。
これはプログラム上で要求している環境変数を設定していないため発生しています。
この環境変数は後々使うのですが、ここで設定しておきましょう。
Test Event Name
testEvent
Response
{
"errorMessage": "'CHROMEDRIVER_PATH'",
"errorType": "KeyError",
"stackTrace": [
" File \"/var/lang/lib/python3.7/imp.py\", line 234, in load_module\n return load_source(name, filename, file)\n",
" File \"/var/lang/lib/python3.7/imp.py\", line 171, in load_source\n module = _load(spec)\n",
" File \"<frozen importlib._bootstrap>\", line 696, in _load\n",
" File \"<frozen importlib._bootstrap>\", line 677, in _load_unlocked\n",
" File \"<frozen importlib._bootstrap_external>\", line 728, in exec_module\n",
" File \"<frozen importlib._bootstrap>\", line 219, in _call_with_frames_removed\n",
" File \"/var/task/lambda_function.py\", line 13, in <module>\n CHROMEDRIVER_PATH = os.environ[\"CHROMEDRIVER_PATH\"]\n",
" File \"/var/lang/lib/python3.7/os.py\", line 681, in __getitem__\n raise KeyError(key) from None\n"
]
}
環境変数を設定する
Lambda関数に環境変数を設定しておきましょう。
ローカルから動作確認する際と、AWS上で実行する場合とで値を切り替えたいことがあるので、このように外部変数に切り出しています。
Labdaの「設定」→「環境変数」に進みます。
以下のキー、値を登録しましょう。
値に設定しているパスは後々の工程で指定したものと一致させる必要があるので、こうしています。
|
キー
|
値
|
|---|---|
| CHROMEDRIVER_PATH | /opt/chromedriver |
| HEADLESS_CHROMIUM_PATH | /opt/headless-chromium |
もう一度「Test」を実行してみましょう。
エラーが変わりましたね。
これは、seleniumから起動するchromedriveをインポート出来ていないのでエラーになってしまっています。
Test Event Name
testEvent
Response
{
"errorMessage": "Message: 'chromedriver' executable needs to be in PATH. Please see https://chromedriver.chromium.org/home\n",
"errorType": "WebDriverException",
"stackTrace": [
" File \"/var/task/lambda_function.py\", line 31, in lambda_handler\n options=options\n",
" File \"/opt/python/selenium/webdriver/chrome/webdriver.py\", line 73, in __init__\n service_log_path, service, keep_alive)\n",
" File \"/opt/python/selenium/webdriver/chromium/webdriver.py\", line 90, in __init__\n self.service.start()\n",
" File \"/opt/python/selenium/webdriver/common/service.py\", line 83, in start\n os.path.basename(self.path), self.start_error_message)\n"
]
}
次に、chromedriverをインストールしましょう。
chromedriverをインストールしてレイヤーに追加する
# linuxのchrome driverをインストールします
# これもバージョンの相性があるので、以下でインストールしたバージョンを使用しましょうcurl -SL https://chromedriver.storage.googleapis.com/2.37/chromedriver_linux64.zip > chromedriver.zipcurl -SL https://github.com/adieuadieu/serverless-chrome/releases/download/v1.0.0-37/stable-headless-chromium-amazonlinux-2017-03.zip > headless-chromium.zip
# 2つのファイルを1つにまとめたいので、一旦解凍します
unzip -o chromedriver.zip -d .
unzip -o headless-chromium.zip -d .# ゴミファイルは削除rm chromedriver.ziprm headless-chromium.zip# レイヤーに追加するためにzipで圧縮しますzip headless.zip chromedriver headless-chromium
ここまで出来たら、先程の同じ要領で「headless.zip」をレイヤーに追加します。
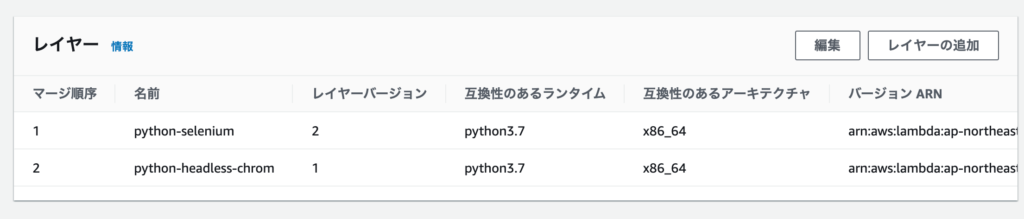
この時点で「selenium + パッケージ」と「chromeドライバ」の2つのレイヤーが追加されていればOKです。
それでは「Test」をまた実行しましょう。
エラーが変わりましたね。
Lambdaは長時間実行されないように、デフォルトのタイムアウト時間が3秒になっています。タイムアウト時間を長く設定してあげる必要があります。
Test Event Name
testEvent
Response
{
"errorMessage": "2023-10-24T09:51:22.560Z 4dfacbfb-b7f4-48a9-9a0b-9c46b2d086c6 Task timed out after 3.01 seconds"
}
次は細々した設定が増えるので、次の章に記載します。
細々とした設定をする
まずは、先程のエラーを解消するためにタイムアウト値を設定します。
「設定」→「一般設定」に飛びます。
編集からタイムアウト値を変えましょう。
とりあえず30秒にしておきます。
再度「Test」を実行します。
またまたタイムアウトしました。
Test Event Name
testEvent
Response
{
"errorMessage": "2023-10-24T09:55:22.997Z 8dc756b9-5599-4b7a-8c6f-f3119f83c93d Task timed out after 30.06 seconds"
}
Function Logs
START RequestId: 8dc756b9-5599-4b7a-8c6f-f3119f83c93d Version: $LATEST
2023-10-24T09:55:22.997Z 8dc756b9-5599-4b7a-8c6f-f3119f83c93d Task timed out after 30.06 seconds
END RequestId: 8dc756b9-5599-4b7a-8c6f-f3119f83c93d
REPORT RequestId: 8dc756b9-5599-4b7a-8c6f-f3119f83c93d Duration: 30060.24 ms Billed Duration: 30000 ms Memory Size: 128 MB Max Memory Used: 128 MB Init Duration: 234.73 ms
以下のエラーに注目です。
Lmabdaに割り当てているメモリが128MBで、128MB全て使い切っていますね。
Memory Size: 128 MB Max Memory Used: 128 MB Init Duration: 234.73 ms
処理の中でChromeを起動するので、かなりメモリを消費するはずです。
ここがボトルネックになっているように見えます。
ということでメモリの割り当てを増やしましょう。
先程と同様に一般設定から「編集」ボタンを押して、メモリの割り当てを増やします。
とりあえず、1024MB(1GB)に増やしておきましょう。
変更したら、またまた「Test」を実行します。
ようやく正常終了しました。
メモリの消費量を見つつ、増やしすぎだと思ったらチューニングしましょう。
(実行したい処理によってメモリの消費量は変わると思うので、各調整してください)
Test Event Name
testEvent
Response
null
Function Logs
START RequestId: ea543588-dad1-47d5-bf5d-2334ab113825 Version: $LATEST
END RequestId: ea543588-dad1-47d5-bf5d-2334ab113825
REPORT RequestId: ea543588-dad1-47d5-bf5d-2334ab113825 Duration: 3937.23 ms Billed Duration: 3938 ms Memory Size: 1023 MB Max Memory Used: 227 MB Init Duration: 200.19 ms
これにて環境構築は終了です。
構築においては、以下の記事を参考にしました。
ありがとうございます。
ブラウザが動く様子が分からないので、デバックの際にはローカルからpythonを起動する必要があります。
ローカルでLambdaを動かしたい場合には、以下の記事が参考になります。

python 3.7.3のインストールで躓く場合には以下をご覧くださいませ。
まとめ
今回は、Lambdaからseleniumを起動するまでの手順をエラードリブンにまとめました。
私が2日潰してしまった作業を、みなさまが1時間程度で実行できるようになったのではないでしょうか?
説明を省いている箇所もあるので、質問などがあれば、TwitterででもDMください。

