




Debezium運用上の停止/起動の気になるポイントと対策
DBのデータの変更をウォッチし、メッセージを送信出来るDebeziumですが、
実際に運用するとなると、サービスのメンテに伴うDebeziumの起動停止にまつわる影響が気になります。
Debeziumを動かすところまでの記事は色々まとまっているのを見つけられたのですが、
実際に運用する際の起動停止に関わる記事が見つからなかったので、
自分なりに調査した結果をまとめています。
検証上の都合、DebeziumとKafkaを主に利用しています。
Debeziumって何?という方は以下の公式ドキュメントをご覧くださいませ。
https://debezium.io/
本記事の目的
- DebeziumとKafkaの連携イメージをざっくりと紹介する
- Debeziumの起動/停止のメンテナンス時に気になる事柄を紹介する
本記事の対象者
- Debezium & Kafkaの運用を検討している人
- Debeziumを安全に止めるにはどうすればいいの?と悩んでいる人
Debezium & Kafkaの動作イメージ
何となく全体像のイメージを掴んでおくのも大事です。
デザインパターンによって細かな違いはあるかもしれないですが、
ざっくり以下のようなイメージです。
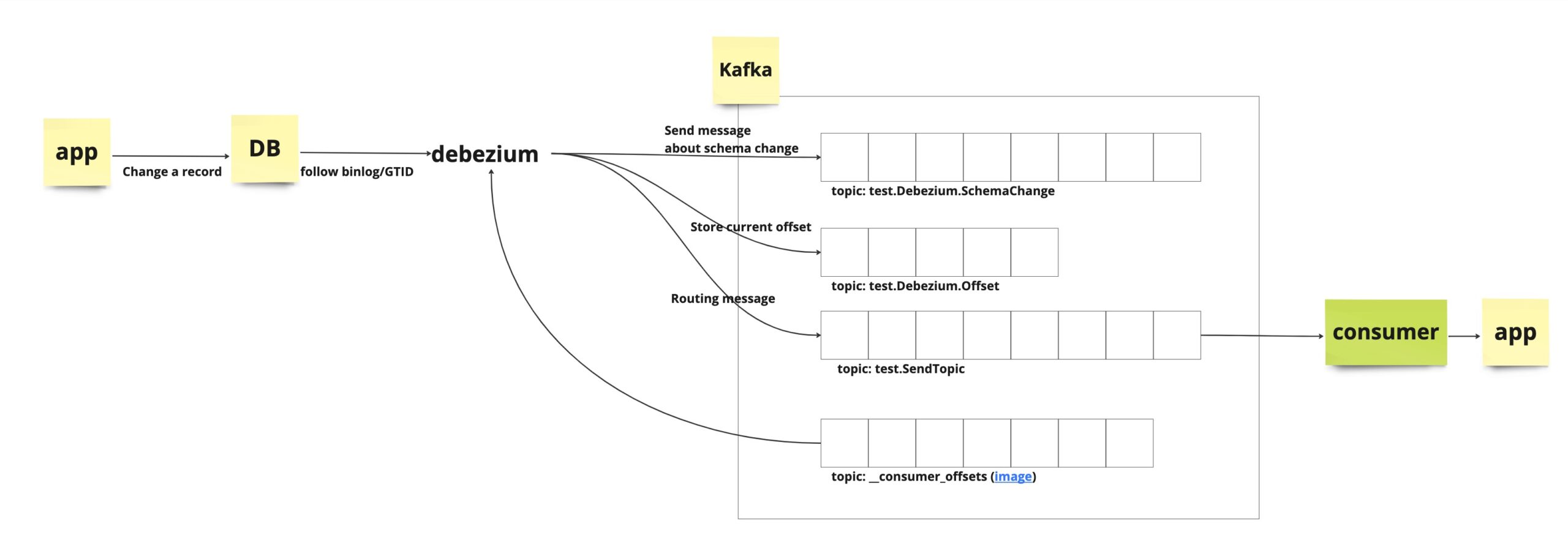
- アプリケーションがDB内のレコードに変更を加える
- DB内のbinlog/GTIDが進む
- binlog/GTID等を基にDBの変更をウォッチしているDebeziumが変更を検知する
- DebeziumがKafkaの特定のトピックに対してメッセージを送信する
- 該当のトピックをSubscribeしているConsumerがメッセージを受信する
- Consumerの先のアプリケーション側でも、何かしらのアクションを取る
その他、Debeziumに関するメタデータ(スキーマの変更情報、Debeziumが読み込んだメッセージに関するオフセットの情報等)も併せて特定のトピックに保存されます。
ハンズオンで動作の検証
以下の公式ドキュメントに沿って、ハンズオンを進められます。
https://debezium.io/documentation/reference/stable/tutorial.html
また、公式のドキュメントでは無いものの、以下のドキュメントに沿うと
Debezium & Kafkaの起動等、完全に1から確かめることが出来ます。
https://zenn.dev/stafes_blog/articles/ikkitang-691e9913644952
非常に丁寧に手順が記載されているので、私も参考にさせていただきました。
運用時に気になること集
細かなコマンドは上記のチュートリアルを進めた前提となっています。
また、基本的には、Kafka Command-Line Interface (CLI) Tools を使って諸々の情報を拾います。
https://docs.confluent.io/kafka/operations-tools/kafka-tools.html
Debeziumの起動状態を確認するには?
Connectorのステータスを確認する (ref)。
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status
{"name":"debezium-sample-connector","connector":{"state":"RUNNING","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.19.0.5:8083"}],"type":"source"}%Debeziumは停止/起動するには?
Connectorを一時停止/再開する
一時停止
~/D/g/debezium ❯❯❯ curl -X PUT http://localhost:8083/connectors/debezium-sample-connector/pause main ◼
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status main ◼
{"name":"debezium-sample-connector","connector":{"state":"PAUSED","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"PAUSED","worker_id":"172.19.0.5:8083"}],"type":"source"}% 再開
~/D/g/debezium ❯❯❯ curl -X PUT http://localhost:8083/connectors/debezium-sample-connector/resume main ◼
~/D/g/debezium ❯❯❯ curl -X GET http://localhost:8083/connectors/debezium-sample-connector/status main ◼
{"name":"debezium-sample-connector","connector":{"state":"RUNNING","worker_id":"172.19.0.5:8083"},"tasks":[{"id":0,"state":"RUNNING","worker_id":"172.19.0.5:8083"}],"type":"source"}%Debezium自体を止める
これはシンプルにDebeziumを止めます。
k8s上で起動している場合には、Podを止めます。
Debezium再起動後に何を確認すればいい?
ざっくり観点は以下の通り
- Debeziumのstatusは
Runningになっているか - Debeziumの現在のオフセットは正しいか(メッセージの二重送信がされていないか)
- Sucscriberは最新のメッセージを受信出来ているか(E2E的な確認)
DebeziumのstatusはRunningになっているか
Debeziumの起動状態を確認するには? に記載したコマンドを実行する。
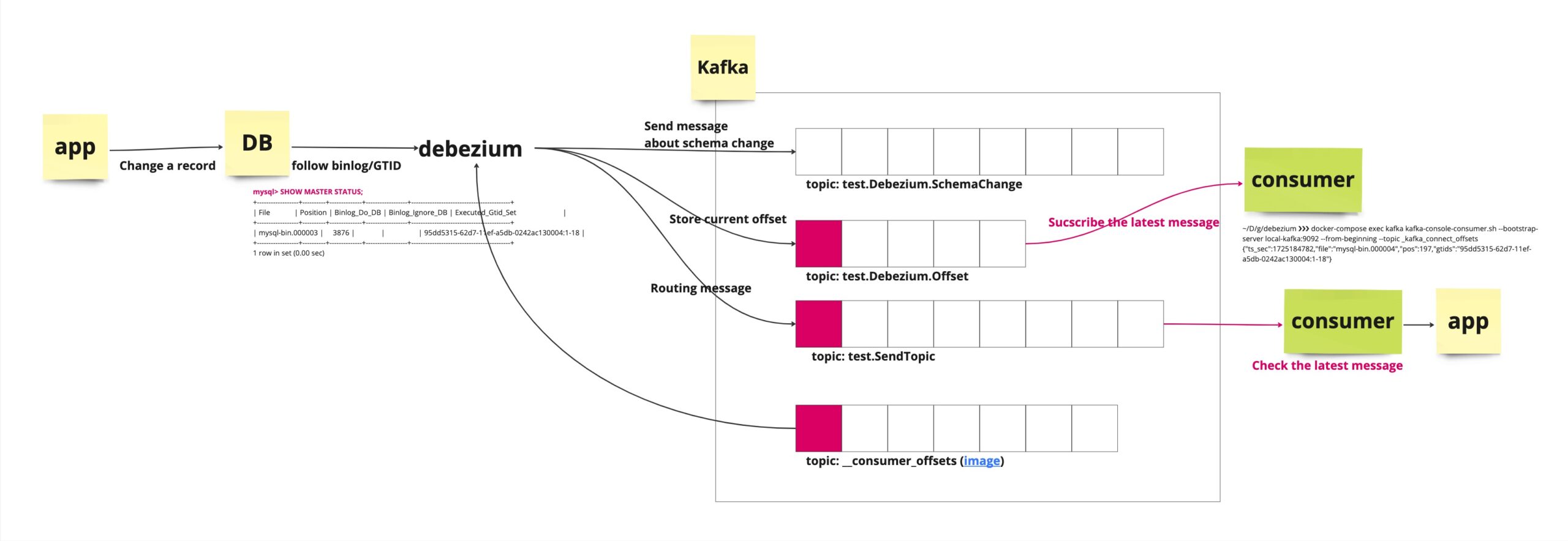
Debeziumの現在のオフセットは正しいか
DB側のbinlogまたはGTIDと、Kafka側に存在するDebeziumのオフセットを管理するトピックのGTIDとが一致することを確認します。
MySQLの場合
mysql> SHOW MASTER STATUS;
+------------------+----------+--------------+------------------+-------------------------------------------+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+------------------+----------+--------------+------------------+-------------------------------------------+
| mysql-bin.000003 | 3876 | | | 95dd5315-62d7-11ef-a5db-0242ac130004:1-18 |
+------------------+----------+--------------+------------------+-------------------------------------------+
1 row in set (0.00 sec)なお余談ですが、MySQLの場合、GTIDを有効化しておくと、binlogのポジションが移行等で変わってしまったとしても、Debeziumが正しい位置から変更を読み込んでくれます。GTIDを有効化していない場合は、MySQLの設定から有効化しておくのがオススメです。
ref: https://debezium.io/documentation/reference/stable/connectors/mysql.html#enable-mysql-gtids
Debezium
後者のDebezium側のオフセットのトピック名は、Debezium起動時に環境変数OFFSET_STORAGE_TOPICで指定できます。
ref: https://hub.docker.com/r/debezium/connect
上記のトピックをSubscribeするConsumerを起動します。
~/D/g/debezium ❯❯❯ docker-compose exec kafka kafka-console-consumer.sh --bootstrap-server local-kafka:9092 --from-beginning --topic _kafka_connect_offsets
{"ts_sec":1725184782,"file":"mysql-bin.000004","pos":197,"gtids":"95dd5315-62d7-11ef-a5db-0242ac130004:1-18"}あとはbinlong/GTIDが一致することを確認しましょう。
注意事項
AWSのAuroraを使っていると、AWS側の仕組みでheartbeat用のクエリが自動的に飛んでくることがあります。これにより、アプリケーション側から変更を加えていないにも関わらずGTIDが進んでしまう。というケースも考えられます。
最新のGTIDがズレていた場合には、こちらのケースも疑いましょう。
Sucscriberは最新のメッセージを受信出来ているか
これは、メッセージを送信する元のアプリケーションを実際に動かして、
メッセージを受信する先側のアプリケーションが正しく想定した処理が起動しているか、受信したメッセージが正しいかどうかを確認します(ログ設計が大事ですね…)。
Debezium再起動時に、メッセージの重複は発生しない?
これは、基本的には発生しないように、DebeziumやKafka側で必要なメタデータを持っています。
Kafka側でのoffsetの管理
Kafkaでは __consumer_offsets というようなトピックを持っていて、各Subscriberがどこまでのメッセージを消費したのかのオフセットを持っているようです。
ref: https://kafka.apache.org/documentation/#impl_offsettracking
keyは [Group, Topic, Partition] の複合キーとなっているため、
これらのkeyが同じSubscriberであれば、再起動時にも適切なオフセットからメッセージをConsumeすることが出来るようです。
こちらのQ&Aに記載されているイメージ図がとても参考になります。
ref: https://stackoverflow.com/questions/56947184/how-does-consumer-offsets-keep-offset-for-two-consumers
各キーの値を理解するには、以下の記事も参考になります。

例外
ただし、例外もあり、これらのメタデータが正しく保存される前にDebeziumやKafka等がクラッシュしてしまうと、勿論ですがメッセージの重複は発生します。
ref: https://debezium.io/documentation/faq/#what_happens_when_debezium_stops_or_crashes
そのため、Consumeするアプリケーション側でもメッセージの重複が発生する可能性は考慮した上で、アプリケーション側も設計する必要がある旨、Debeziumのドキュメントにも記載があります。
ref: https://debezium.io/documentation/faq/#why_must_consuming_applications_expect_duplicate_events
まとめ
今回は、実際にDebeziumを運用する際に気になるであろう内容をまとめました。
Kafkaについても今回初めて軽く調査しました。
ConsumerやらSubscriberやら、いくつかKafkaで扱われる用語もあって混乱しています。用語の用法に誤りがある場合、こそっと教えていただけると幸いです。
ここまで見ていただきありがとうございました。


