




「達人が教えるWebパフォーマンスチューニング」を進めながら、サンプルアプリのボトルネック探しとパフォーマンスの改善をしてみました。
どんな流れで、どんなコマンドを使ったのかを簡単に紹介します。

ボトルネック調査やパフォーマンス改善の思考の過程の詳細を知りたい場合。上記書籍をお手元にご準備いただくのをオススメします。
想定する読者
- Webの性能試験をする上で、どんな流れで進めるのか触りを知りたい人
- 性能試験を進める上で、活用できるコマンドを知りたい人
実施したこと
基本的な流れとしては、こんな感じです。
- 事前準備
- 実行結果を確認するためのログ出力の設定をする
- 負荷試験の実施
- ベンチマーカーで負荷をかける
- 負荷試験中のシステムを監視する
- 実行結果を確認して、ボトルネックを調べる
- チューニングを行う
事前準備
ログ出力の設定やコマンドのインストールなどを済ませます。
以下の環境構築記事を一通りなぞっていれば、準備OKだと思います。

負荷試験の実施
ベンチマーカーを使って負荷をかけます(後ろで紹介しているabコマンドを使いました)。
負荷試験中には、top, dstat等のコマンドを使用して、システムのリソース利用状況を監視しました。
- CPUが暇を持て余していないか
- リクエストが詰まっている(ネックになっている)のがどの部分か
なんてことを考えながら、監視していました。
ボトルネックの調査
負荷試験が終わったら、ログを確認しながらボトルネックを調べていきます。
シンプルなWebアプリケーションの構成の場合、以下のような項目をまず先に見にいくことでしょう。
- Webサーバのアクセスログを確認する
- SQLの実行結果(SlowQueryログ)を確認する
- システムリソースの利用状況と照らし合わせる
負荷がかかっている(CPUがパンパンである)わけではないのに、処理速度が伸びない ということがあれば、どこかで処理が詰まっていることを疑う等、いくつか定番の観点があるようです。
書籍の中で、いくつかの観点が紹介されていて参考になりました。
パフォーマンスの改善
すぐに修正できる範囲で実施したこととしては以下の通りです。
- データベースのテーブルへのIndex付与
- これだけでスループットが50倍くらいになりました
- Webサーバのワーカー数の増加
- CPUが遊んでいた
- リクエストの並列数を1 → 2 → 4と増やした際に、リクエストあたりの待ち時間が線形的に増えていた
- 上記のようなことを確認し、Webサーバのワーカが少ないことを疑った
この辺は、経験を積んで引き出しを増やしていくしかなさそう。
便利なコマンド
ボトルネック調査、パフォーマンス改善の際に活躍するコマンドについて、
使えそうなコマンドテンプレをまとめてみました。
アクセスログ解析 – alpコマンド
nginxのアクセスログを解析するために利用出来ます。
GitHub: https://github.com/tkuchiki/alp
集計対象
timemethoduristatusresponse_timerequest_time
# シンプルな使い方
cat access.log | alp json
+-------+-----+-----+-----+-----+-----+--------+----------------------+-------+-------+-------+-------+-------+-------+-------+--------+-------------+-------------+-------------+-------------+
| COUNT | 1XX | 2XX | 3XX | 4XX | 5XX | METHOD | URI | MIN | MAX | SUM | AVG | P90 | P95 | P99 | STDDEV | MIN(BODY) | MAX(BODY) | SUM(BODY) |AVG(BODY) |
+-------+-----+-----+-----+-----+-----+--------+----------------------+-------+-------+-------+-------+-------+-------+-------+--------+-------------+-------------+-------------+-------------+
| 1 | 0 | 1 | 0 | 0 | 0 | GET | /favicon.ico | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 43.000 | 43.000 | 43.000 | 43.000 |
| 1 | 0 | 1 | 0 | 0 | 0 | GET | /css/style.css | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 0.000 | 1549.000 | 1549.000 | 1549.000 | 1549.000 |
| 1 | 0 | 1 | 0 | 0 | 0 | GET | /img/ajax-loader.gif | 0.004 | 0.004 | 0.004 | 0.004 | 0.004 | 0.004 | 0.004 | 0.000 | 673.000 | 673.000 | 673.000 | 673.000 |
# -rをつけると、降順になる。アクセスされたURIの多い順でソート
cat access.log | alp json -r
# --srot=xxx で指定したカラムでソート。URI別のレスポンスタイムの合計が多い順。
cat access.log | alp json --sort=sum -r
# URI別のレスポンスタイムの平均が大きい順
cat access.log | alp json --sort=avg -r
# -o xxx,xxx, ...とすると表示内容を絞れる。
cat access.log | alp json -o count,method,uri,min,avg,max
+-------+--------+-----+-------+-------+-------+
| COUNT | METHOD | URI | MIN | AVG | MAX |
+-------+--------+-----+-------+-------+-------+
| 10 | GET | / | 1.360 | 1.365 | 1.372 |
+-------+--------+-----+-------+-------+-------+
# avg, sum, p99あたりはよく使いそう
cat access.log | alp json -o count,method,uri,avg,sum,p99 -r
# '/image/1863.jpg'のようなクエリ部分をまとめて集計したい場合
cat access.log | alp json -o count,method,uri,avg,sum,p99 -r -m "/image/[0-9]+"
+-------+--------+----------------------+-------+-------+-------+
| COUNT | METHOD | URI | AVG | SUM | P99 |
+-------+--------+----------------------+-------+-------+-------+
| 185 | GET | /image/[0-9]+ | 0.002 | 0.416 | 0.024 |
| 8 | GET | / | 0.089 | 0.712 | 0.256 |
# 5xxのエラーが発生しているリクエストを探す
cat access.log | alp json -o count,method,uri,5xx -r
# アクセスログがjson形式ではなくデフォルトの場合
cat access.log | alp regexp
結構便利。障害発生時にアクセスログを地道にgrepするよりもいいかも。
ベンチマーカー – abコマンド
多重度やリクエストを指定して、さくっと負荷をかけられる。
ベンチマーカーのインストール
sudo apt update
sudo apt install apache2-utils
# 基本的な使い方
# 並列度は1で10回リクエストを送信する。送信先はlocalhost
ab -c 1 -n 10 http://localhost/
# KeepAliveを有効化
ab -c 1 -n 10 -k http://localhost/
# 試行時間を30秒として、リクエストを送信する
ab -c 1 -t 30 http://localhost/
# レスポンスのサイズがリクエストごとに異なっても失敗にしない。動的なページで使える。
ab -c 1 -t 30 -l http://localhost/
# Postの場合は少々複雑
# -pでPostするBodyのファイルを指定
ab -c 1 -t 30 -p ./sample.json -T "application/json; charset=utf-8" "http://localhost/hogehoge"
単体レベルのテストをするには良さそう。
複雑なシナリオが必要になる場合だと、向かない。
# 簡単に読み方
$ ab -c 1 -n 10 http://localhost/
This is ApacheBench, Version 2.3 <$Revision: 1879490 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking localhost (be patient).....done
Server Software: nginx/1.18.0
Server Hostname: localhost
Server Port: 80
Document Path: /
Document Length: 35644 bytes
Concurrency Level: 1 # 並列度
Time taken for tests: 13.651 seconds # 完了までの経過時間
Complete requests: 10 # 成功したリクエスト数
Failed requests: 0 # 失敗したリクエスト数
Total transferred: 360160 bytes # サーバから転送されたバイト数の合計
HTML transferred: 356440 bytes
Requests per second: 0.73 [#/sec] (mean) # 1秒間あたりに処理できたリクエスト数
Time per request: 1365.054 [ms] (mean) # 1リクエスト処理するのにかかった経過時間
Time per request: 1365.054 [ms] (mean, across all concurrent requests)
Transfer rate: 25.77 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.0 0 0
Processing: 1360 1365 3.8 1365 1372
Waiting: 1360 1365 3.8 1365 1372
Total: 1360 1365 3.8 1365 1372
Percentage of the requests served within a certain time (ms)
50% 1365
66% 1366
75% 1367
80% 1369
90% 1372
95% 1372
98% 1372
99% 1372
100% 1372 (longest request)
```
Requests per second: 0.73 [#/sec] (mean) # 1秒間あたりに処理できたリクエスト数
Time per request: 1365.054 [ms] (mean) # 1リクエスト処理するのにかかった経過時間
スループットと処理時間がよく見るポイント。
スロークエリの解析 – mysqldumpslow
SlowQueryを集計するために使用する。
mysqlインストール時に付属しているので、特にインストールは不要。
# 実行時間の合計が長い順に出力される
sudo mysqldumpslow /var/log/mysql/mysql-slow.log
# こんな感じに集計される
Reading mysql slow query log from /var/log/mysql/mysql-slow.log
Count: 1716 Time=0.05s (77s) Lock=0.00s (0s) Rows=3.0 (5148), isuconp[isuconp]@localhost
SELECT * FROM `comments` WHERE `post_id` = N ORDER BY `created_at` DESC LIMIT N
1回あたりのクエリ実行時間が短い場合でも、大量の数のクエリが実行されていて、処理時間に占めるクエリ実行時間の割合が膨大になっている可能性もあるので、注意が必要。
クエリの実行時間やRows(n行返すために、何行アクセスしに行ったのか)等からボトルネックの原因を考えていくことができる。
CPUやメモリやプロセスやらのウォッチ – top
色々ウォッチできます。
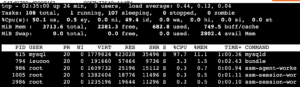
CPUのコア数が2以上の場合、上に出ているCPUと下に出ているCPUの分母の意味合いが変わるので注意が必要。私もいつも「あれ?どっちだったっけ?」となります。
上の方は分母がマシン全てのCPU。
下の方は、1コア分のCPU。下の方がコア数が多いと、CPU利用率を合計したときに100%を超えることもあるわけですね。
システムメトリクスの表示 – dstat
dstat –cpuコマンドを使って、CPU使用率を簡単にウォッチできます。
GitHub: https://github.com/dstat-real/dstat
$ dstat --cpu
--total-cpu-usage--
usr sys idl wai stl
4 1 95 0 0
0 0 100 0 0
0 0 100 0 0
0 0 99 0 0
0 0 100 0 0
0 0 100 0 0
15 3 81 0 0
48 9 43 0 0
50 8 42 0 0
48 9 43 0 0
49 9 43 0 0
47 9 44 0 0
49 7 44 0 0
idl: CPUが処理を行っておらず、暇な状態であることを表す。
今までvmstatを使ってきたのですが、こっちの方が結構読みやすい。
現在は開発が止まっていて、doolが後継として開発されている模様。
GitHub: https://github.com/scottchiefbaker/dool
おわりに
ざっくりと、負荷試験の流れと便利なコマンド集を紹介しました。
シナリオを作っての負荷試験を準備したことはあるのですが、abコマンドを使って簡単に負荷をかけてみる。というようなことは無かったので勉強になりました。
以上です。




