
Introduction
The k6 tool is useful for performance testing.
The k6 is a good tool, but there is no way to share mutable values among VU(Virtual Users) per scenario if just only use k6.
In this article, I introduce how to resolve the above issue using Redis.
Backgound: want to read CSV in order from top per VU
What motivation?
When we assume the scenario that includes a login function or input data to some forms, we think it’s better to prepare CSV files that include information for login per scenario, and perhaps we try to read CSV in order from the top with only one line per VU.
Furthermore, in this case, VU must read data from CSV if iteration for VU is the first time.
Because VU needs to avoid the change of login user when the iteration is first time and second time.
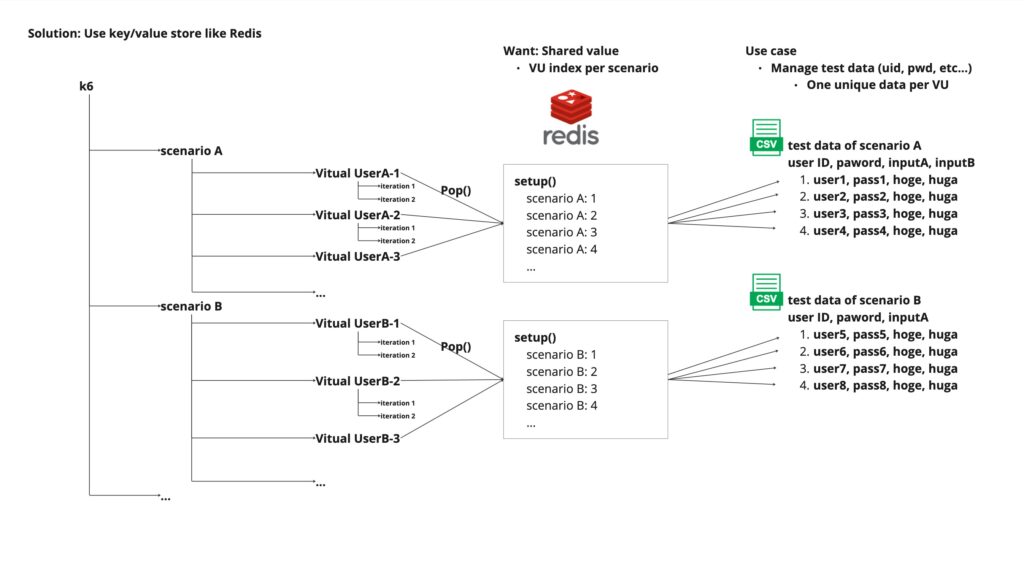
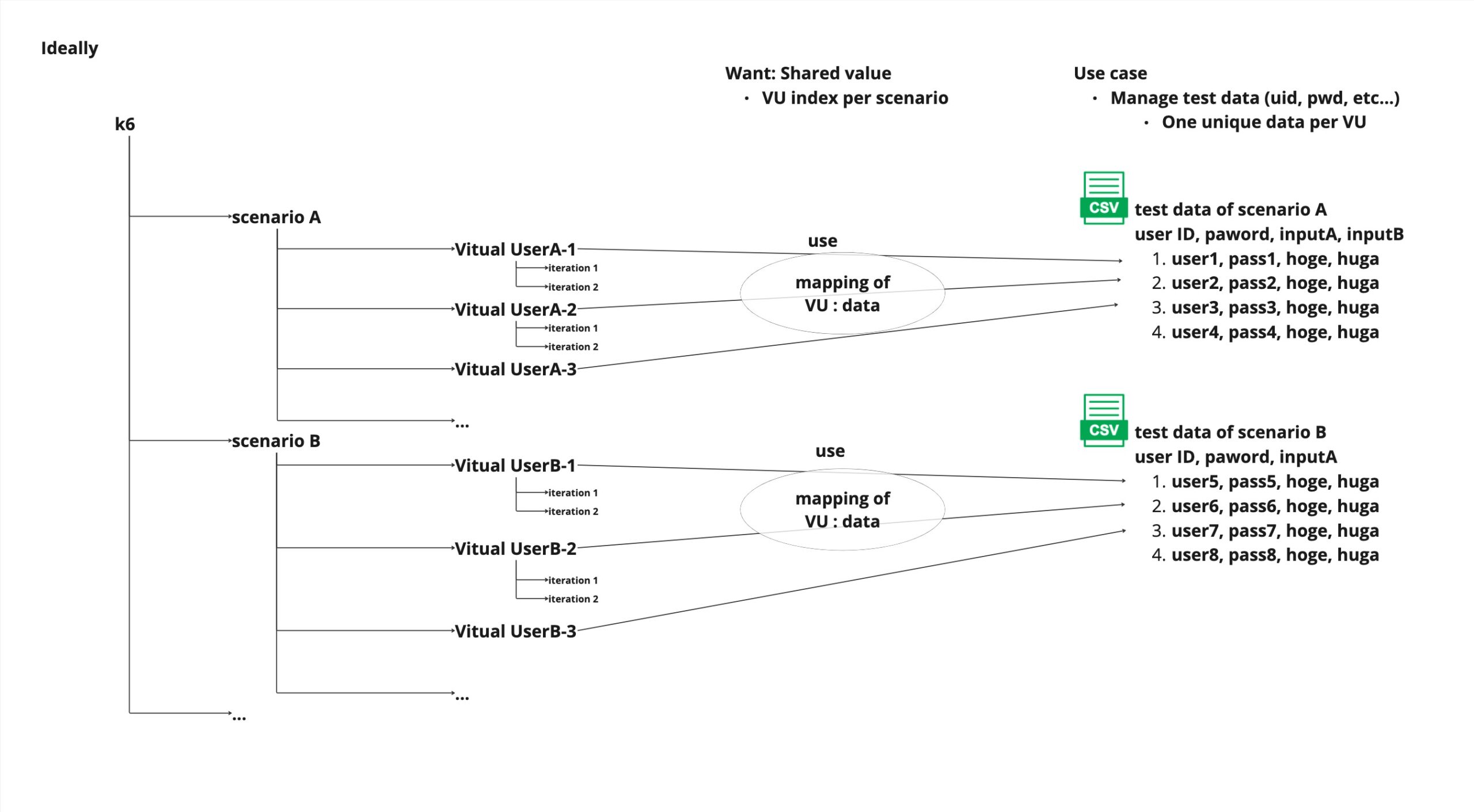
To achieve the above, we need to store the variables that satisfy the following requirements.
- Within the same scenario, index information on how many lines of the CSV file were read by the VU
- The above information is stored independently for each scenario
Those image of requirements is the following figure.
Also there is a sharedArray in k6 to read and pass the CSV file to VU.
https://grafana.com/docs/k6/latest/javascript-api/k6-data/sharedarray/
If the k6 passes user data to each VU, sharedArray is used by setting the index of CSV file like user[ 0 ], user[ 1 ], …
However, sharedArray is an immutable value so sharedArray doesn’t have the feature that gets user data and deletes used data like the pop() method.
So, we need any information that can correctly set the index of sharedArray.
Current issues
Currently (as of writing on 2024/03/17), the k6 can’t provide that information that satisfies the following requirements.
- Within the same scenario, index information on how many lines of the CSV file were read by the VU
- The above information is stored independently for each scenario
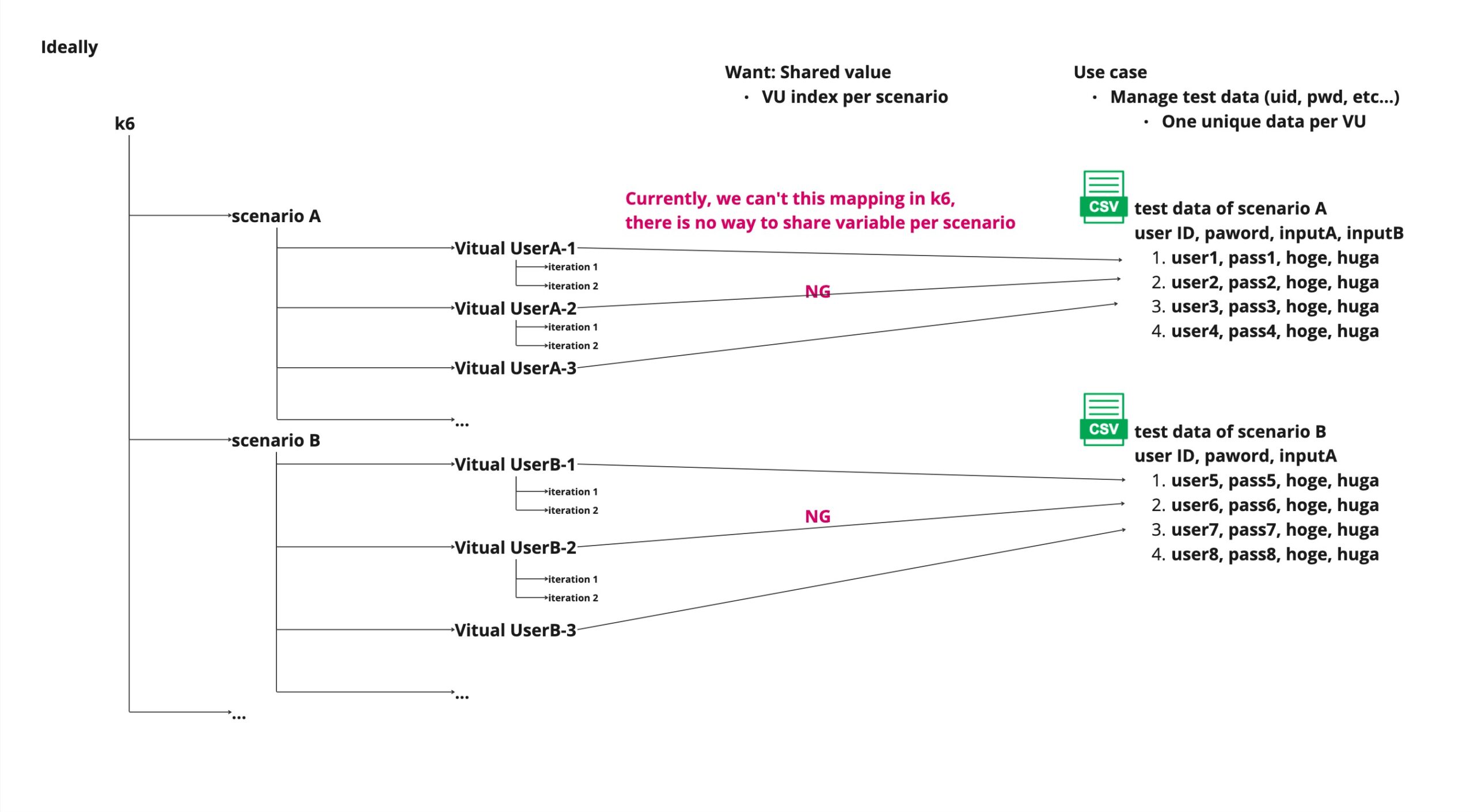 So the k6 can’t do it even if other performance testing tools like Gatling can do it.
So the k6 can’t do it even if other performance testing tools like Gatling can do it.
(Apparently, the k6 assumes that used by the cloud, decentralized use, etc… Thus reluctant to store and use this information inside of k6)
Naturally, there are some users who wanna use it in same way and there are some discussion in community of k6.
For example, the following user has the same issue as me.
Seeing the threads, this issue hasn’t been resolved yet.
https://community.grafana.com/t/shared-state-or-unique-sequential-vu-index-per-scenario/97349
I researched a lot of articles in Japan, but there is a no way to resolve this issue and almost use cases intorduced that using random value for the index of CSV file.
I researched a lot of articles in Japan, but there is a no way to resolve this issue, and almost all use cases introduced that using random values for the index of the CSV file.
(By some chance, It came to my mind that my approach is wrong)
The following discusion, some use cases that how to read data against VUs is listed.
https://github.com/grafana/k6/issues/1539#issuecomment-1022105636
The following content is near to what I want to achieve.
One item per VU, where items < VUs. Cyclical.
https://community.grafana.com/t/when-parameterizing-data-how-do-i-not-use-the-same-data-more-than-once-in-a-test/99720
However, there isn’t a perfect way to read CSV in order from the top on, and it is possible to conflict data among VUs.
Some hacking ways exist but those ways have aspects of demerit.
Let me show some examples with their demerit.
Use execution.scenario.iterationInTest metrics in k6 API
k6 API provide some metrics that relate to scenario during execution and VU.
URL: https://k6.io/docs/javascript-api/k6-execution/#scenario
This is example of using Counter: scenario.iterationInTest.
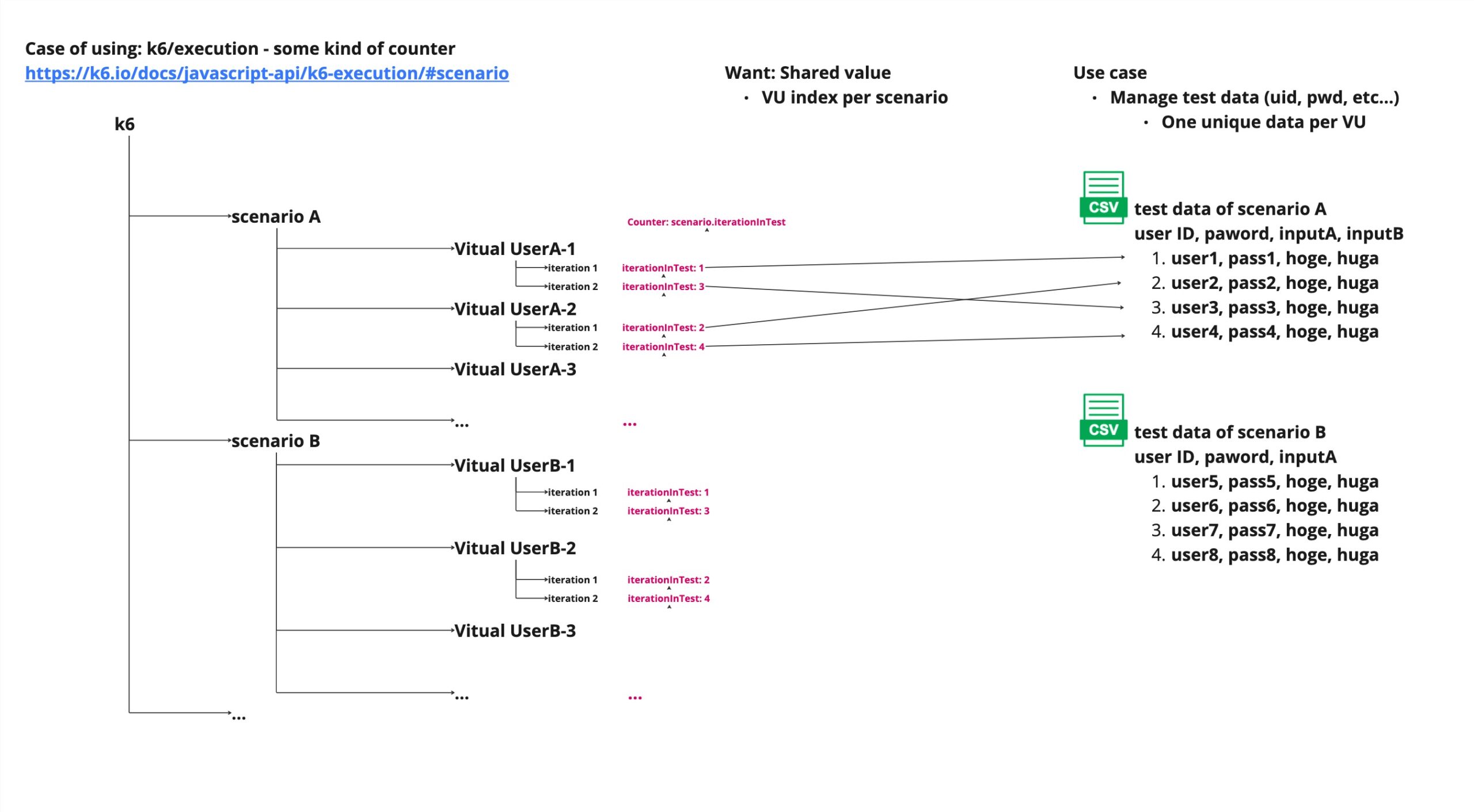
This counter will increment count of executed scenario per scenario.
To combinate scenario.iterationInTest and vu.iterationInScenario, we can read data from CSV using unique index value and can avoid conflict of user data.
However, in this case, CSV data is needed as much as “VU * amount of iterations”.
If preparing a huge test data is difficult, this method will be inappropriate.
Use execution.vu.iterationInTest metrics of k6 API
https://k6.io/docs/javascript-api/k6-execution/#vu
This is sample of using Counter: vu.iterationInTest metrics.
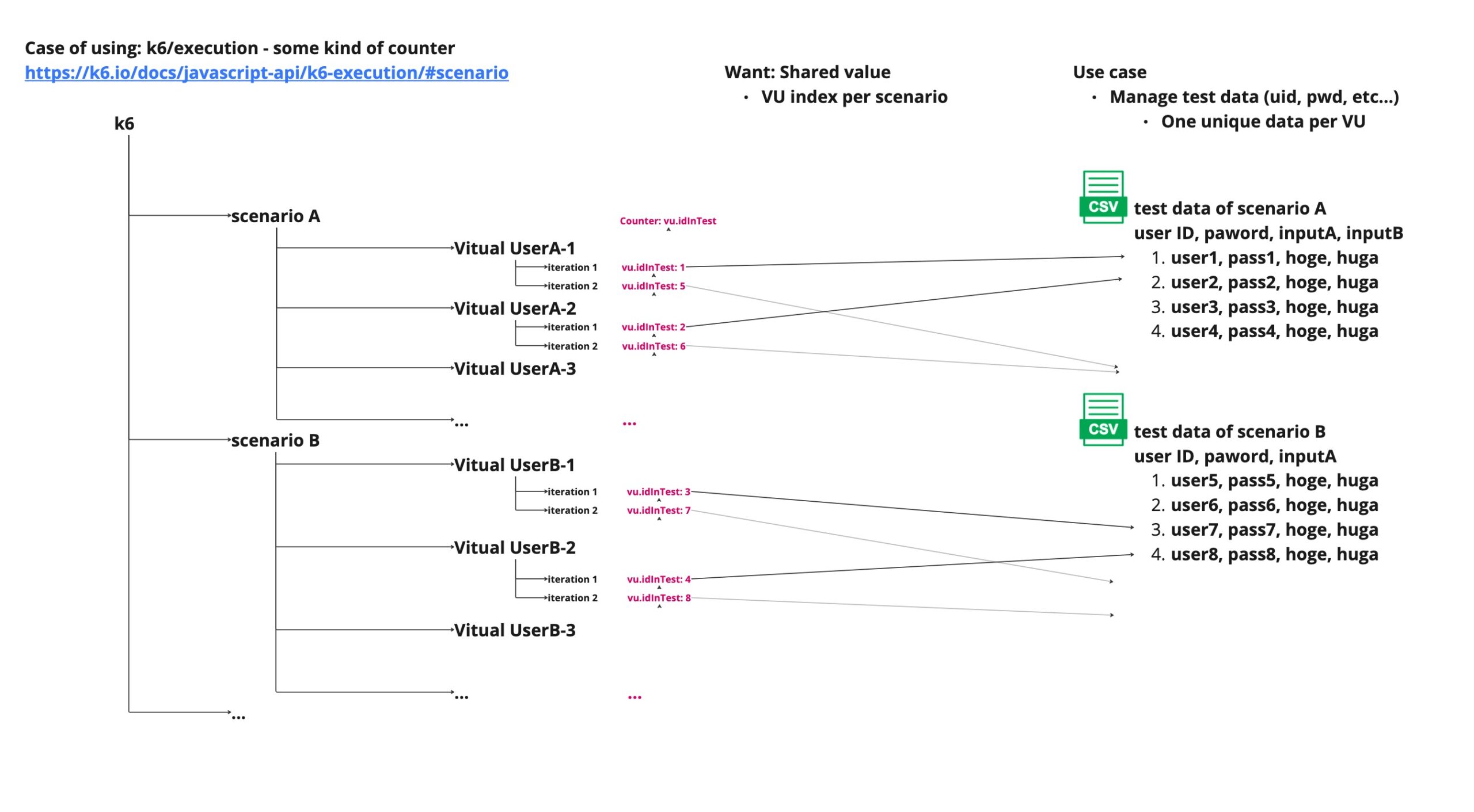 This counter is a unique value against VU that is used in all scenarios.
This counter is a unique value against VU that is used in all scenarios.
So, this value won’t be duplicated.
However, in this case, CSV data is needed as much as all VUs that are used on all scenarios.
If preparing a huge test data is difficult, this method will be inappropriate too.
Use execution.vu.iterationInScenario metrics of k6 API
https://k6.io/docs/javascript-api/k6-execution/#scenario
This is sample of Counter: vu.iterationInScenario metrics.
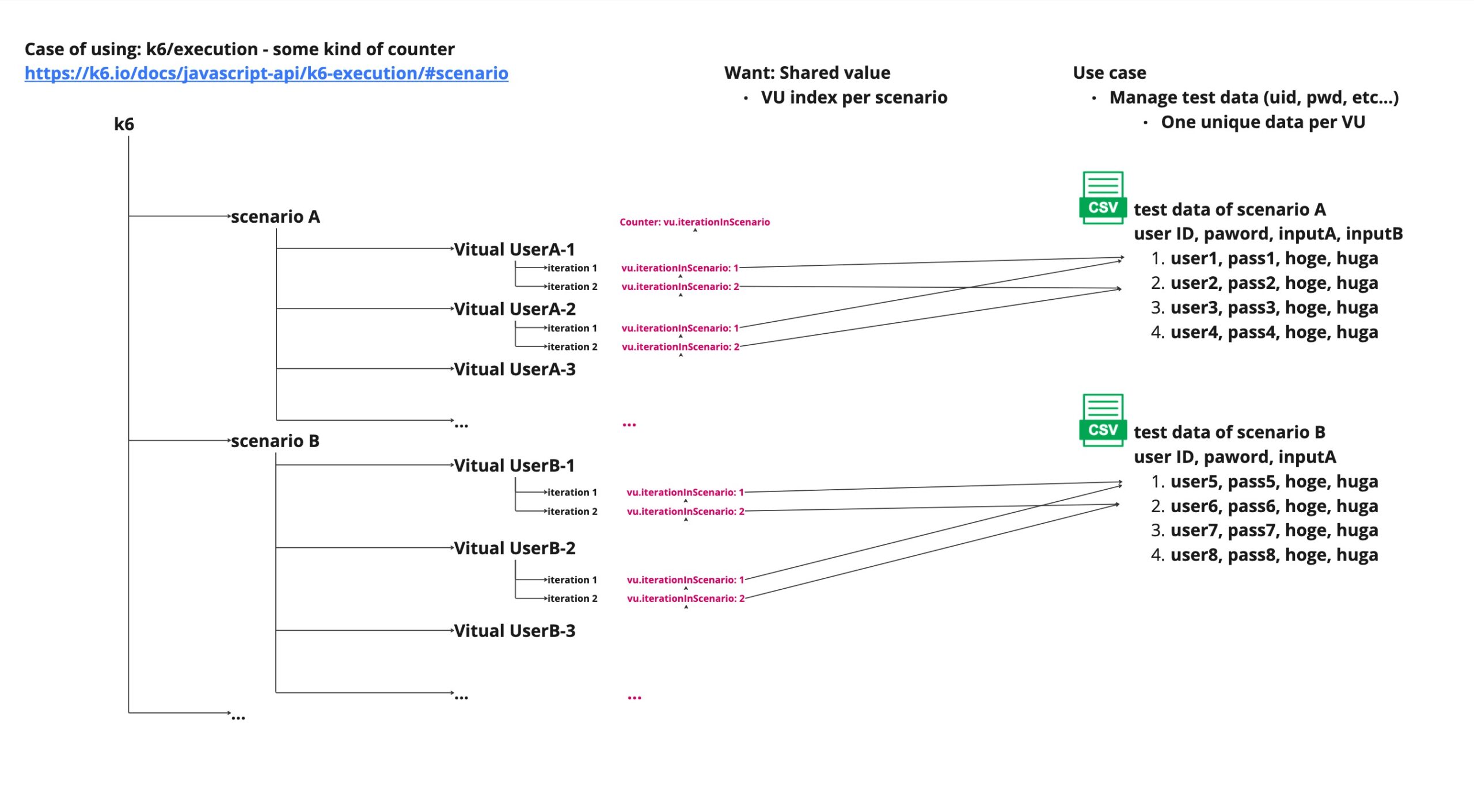 This counter will count the number of iterations per VU.
This counter will count the number of iterations per VU.
Let’s see the above figure and you maybe can understand that user data between VU1 and VU2 is conflicted.
Other ideas (that are not better)
There are some useful features.
- xk6-counter
- https://github.com/mstoykov/xk6-counter
- This is counter that is shared on all scenarios
- If you can prepare a lot of user data (= total of VU), this way is good
- Can’t use in k6-cloud. Can use only local environment
- xk6-kv
- https://github.com/oleiade/xk6-kv
- This feature enable that k6 can have Kye/Value store in local instance
- We can store index for CSV and set/get/delete it per scenario
- There is no feature like pop() method
- So we can’t manage index for CSV in this way
- Exclusion control is not possible
Impossible to obtain an accurate index when the multiplicity of VUs increases
- Exclusion control is not possible
There are some useful metrics and expansion, but the issue of this article couldn’t be resolved.
So, finally,l learned that this issue couldn’t be resolved only by k6, and the shared information must be managed outer data store.
Incidentally, I have also set up an external service to manage indexes for each scenario in Express, MySQL, based on the following community discussion.
https://community.grafana.com/t/unique-test-data-per-vu-without-reserving-data-upfront/97144/4
However, we are concerned that it may become a bottleneck for load testing if it has to withstand the multiplicity of VUs while also considering exclusion control on the DB side. Therefore, we did not choose that method this time.
Solution: Use key/value store like Redis
The preface has taken a long time.
k6 by itself can’t resolve this issue, and setting up an API server will become a bottleneck…
So we thought it would be appropriate to use Redis as a data store that combines speed and integrity.
Fortunately, k6 also provides a Client for Redis operations, so it seems easy to handle.
https://grafana.com/docs/k6/latest/javascript-api/k6-experimental/redis/
The implementation image is the following figure.
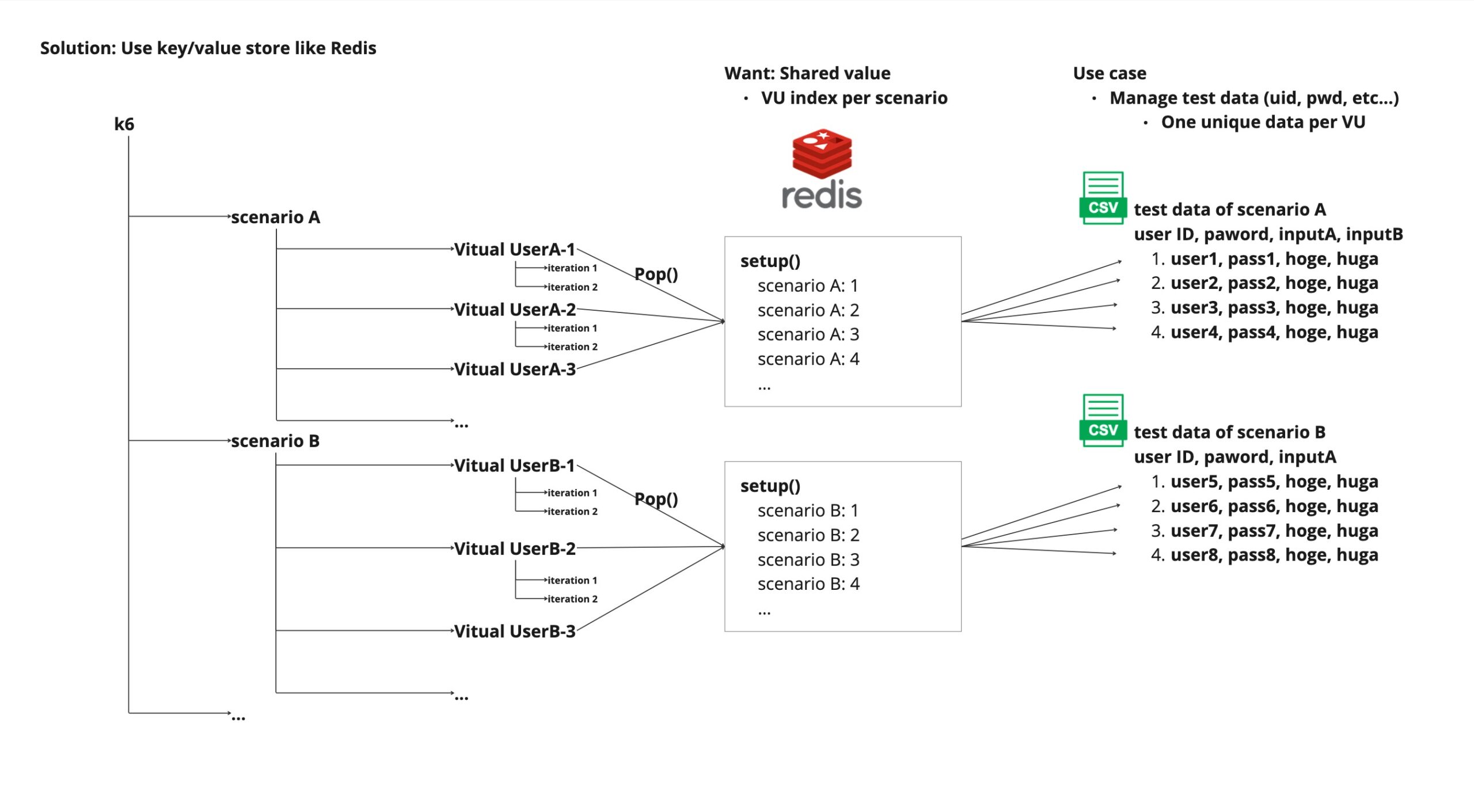
In setup(), before the scenario starts, the index numbers to be used in all scenarios are put into Redis in the form of (scenario name, index number).
After that, by pop() the indexes of the relevant scenario in the scenario, you can retrieve the indexes in order from the top and read the data from the CSV file as expected.
(I have tried this locally with 1000 parallel rows, with no duplicates occurring.)
How to deploy redis in local is discribed in the following document.
Official doc: https://redis.io/docs/install/install-redis/
Below is a sample image of the k6 code.
Data is set into Redis in Setup(), which is called only once before the scenario starts.
import redis from 'k6/experimental/redis'
const client = new redis.Client('redis://localhost:6379')
export async function Setup(): Promise<void> {
for (let i = 0; i < amountOfScenarioIteration; i++) {
await client.rpush('scenarioA', i)
}
}
In the scenario, only for the first iteration, the data will be pop() and used as an index in the CSV.
import { SharedArray } from 'k6/data'
import papaparse from 'https://jslib.k6.io/papaparse/5.1.1/index.js'
import redis from 'k6/experimental/redis'
const client = new redis.Client('redis://localhost:6379')
// Manage whether current iteration is first or not
let roopCounterPerVU = 0
const users = new SharedArray('atTimesIndex', function () {
return papaparse.parse(open(`${SCENARIO_FILES_DIR()}/userdata.csv`), { header: true }).data
})
export default async function ScenarioA(): Promise<void> {
if (roopCounterPerVU === 0) {
const counter = await client.lpop('scenarioA')
user = users[counter]
}
roopCounterPerVU++
}
By simply configuring the scenario in this way, only one line of the CSV file is read per VU, in order from the top. This can be done by simply configuring a scenario like this.
Conclusion
I spent a few days struggling with it, fishing through various pages and official documentation.
If it were Gatling, it would be so easy… Why is k6 ….?
Is this also a JavaScript specification…? Oh, I’m going to hate JavaScript. ….
I was racking my brains with all kinds of thoughts.
I hope someone with the same problem can solve his/her problem in a few hours…
Thank you for taking the time to look this far.